Учебное пособие
Санкт-Петербургский Государственный институт
точной механики и оптики (технический университет)
Кафедра вычислительной техники
Предисловие
Глава 1. Реляционные базы данных и язык SQL
1.1. Реляционная база данных
1.2. Почему SQL?
1.3. Таблицы SQL
Глава 2. Запросы с использованием единственной таблицы
2.1. О предложении SELECT
2.2. Выборка без использования фразы WHERE
2.2.1. Простая выборка
2.2.2. Исключение дубликатов
2.2.3. Выборка вычисляемых значений
2.3. Выборка c использованием фразы WHERE
2.3.1. Использование операторов сравнения
2.3.2. Использование BETWEEN
2.3.3. Использование IN
2.3.4. Использование LIKE
2.3.5. Вовлечение неопределенного значения
2.4. Выборка с упорядочением
2.5. Агрегирование данных
2.5.1. SQL-функции
2.5.2. Функции без использования фразы GROUP BY
2.5.3. Фраза GROUP BY
2.5.4. Использование фразы HAVING
Глава 3. Запросы с использованием нескольких таблиц
3.1. О средствах одновременной работы с множеством таблиц
3.2. Запросы, использующие соединения
3.2.1. Декартово произведение таблиц
3.2.2. Эквисоединение таблиц
3.2.3. Естественное соединение таблиц
3.2.4. Композиция таблиц
3.2.5. Тета-соединение таблиц
3.2.6. Соединение таблиц с дополнительным условием
3.2.7. Соединение таблицы со своей копией
3.3. Вложенные подзапросы
3.3.1. Виды вложенных подзапросов
3.3.2. Простые вложенные подзапросы
3.3.3. Использование одной и той же таблицы во внешнем и вложенном подзапросе
3.3.4. Вложенный подзапрос с оператором сравнения, отличным от IN
3.3.5. Коррелированные вложенные подзапросы
3.3.6. Запросы, использующие EXISTS
3.3.7. Функции в подзапросе
3.4. Объединение (UNION)
3.5. Реализация операций реляционной алгебры предложением SELECT
3.6. Резюме
Глава 4. Предложения модификации данных SQL
4.1. Особенности и синтаксис предложений модификации
4.2. Предложение DELETE
4.2.1. Удаление единственной записи
4.2.2. Удаление множества записей
4.2.3. Удаление с вложенным подзапросом
4.3. Предложение INSERT
4.3.1. Вставка единственной записи в таблицу
4.3.2. Вставка множества записей
4.3.3. Использование INSERT...SELECT для построения внешнего соединения
4.4. Предложение UPDATE
4.4.1. Обновление единственной записи
4.4.2. Обновление множества записей
4.4.3. Обновление с подзапросом
4.4.4. Обновление нескольких таблиц
4.5. О конструировании предложений модификации
Глава 5. О предложениях определения данных и оптимизации запросов
5.1. Системный каталог
5.2. Создание и уничтожение базовых таблиц
5.3. О индексах и производительности
5.4. Представления
5.4.1. Создание и уничтожение представлений
5.4.2. Операции выборки из представлений
5.4.3. Обновление представлений
5.4.4. Для чего нужны представления
Глава 6. О других предложениях и конструкциях SQL
6.1. Безопасность и санкционирование доступа
6.2. Обработка транзакций
6.3. Прикладное программирование
Литература
Все языки манипулирования данными (ЯМД), созданные до появления реляционных баз данных и разработанные для многих систем управления базами данных (СУБД) персональных компьютеров, были ориентированы на операции с данными, представленными в виде логических записей файлов. Это требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены и как шаг за шагом получить их.
Рассматриваемый же ниже непроцедурный язык SQL (Structured Query Language - структуризованный язык запросов) ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений этого языка состоит в том, что они ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных.
Для иллюстрации различий между ЯМД рассмотрим следующую ситуацию. Пусть, например, вы собираетесь посмотреть кинофильм и хотите воспользоваться для поездки в кинотеатр услугами такси. Одному шоферу такси достаточно сказать название фильма - и он сам найдет вам кинотеатр, в котором показывают нужный фильм. (Подобным же образом, самостоятельно, отыскивает запрошенные данные SQL.)
Для другого шофера такси вам, возможно, потребуется самому узнать, где демонстрируется нужный фильм и назвать кинотеатр. Тогда водитель должен найти адрес этого кинотеатра. Может случиться и так, что вам придется самому узнать адрес кинотеатра и предложить водителю проехать к нему по таким-то и таким-то улицам. В самом худшем случае вам, может быть, даже придется по дороге давать указания: "Повернуть налево... проехать пять кварталов... повернуть направо...". (Аналогично больший или меньший уровень детализации запроса приходится создавать пользователю в разных СУБД, не имеющих языка SQL.)
Появление теории реляционных баз данных и предложенного Коддом языка запросов "alpha", основанного на реляционном исчислении [2, 3], инициировало разработку ряда языков запросов, которые можно отнести к двум классам:
Разработка, в основном, шла в отделениях фирмы IBM (языки ISBL, SQL, QBE) и университетах США (PIQUE, QUEL) [3]. Последний создавался для СУБД INGRES (Interactive Graphics and Retrieval System), которая была разработана в начале 70-х годов в Университете шт. Калифорния и сегодня входит в пятерку лучших профессиональных СУБД. Сегодня из всех этих языков полностью сохранились и развиваются QBE (Query-By-Example - запрос по образцу) и SQL, а из остальных взяты в расширение внутренних языков СУБД только наиболее интересные конструкции.
В начале 80-х годов SQL "победил" другие языки запросов и стал фактическим стандартом таких языков для профессиональных реляционных СУБД. В 1987 году он стал международным стандартом языка баз данных и начал внедряться во все распро-страненные СУБД персональных компьютеров. Почему же это произошло?
Непрерывный рост быстродействия, а также снижение энергопотребления, размеров и стоимости компьютеров привели к резкому расширению возможных рынков их сбыта, круга пользователей, разнообразия типов и цен. Естественно, что расширился спрос на разнообразное программное обеспечение.
Борясь за покупателя, фирмы, производящие программное обеспечение, стали выпускать на рынок все более и более интеллектуальные и, следовательно, объемные программные комплексы. Приобретая (желая приобрести) такие комплексы, многие организации и отдельные пользователи часто не могли разместить их на собственных ЭВМ, однако не хотели и отказываться от нового сервиса. Для обмена информацией и ее обобществления были созданы сети ЭВМ, где обобществляемые программы и данные стали размещать на специальных обслуживающих устройствах - файловых серверах.
СУБД, работающие с файловыми серверами, позволяют множеству пользователей разных ЭВМ (иногда расположенных достаточно далеко друг от друга) получать доступ к одним и тем же базам данных. При этом упрощается разработка различных автоматизированных систем управления организациями, учебных комплексов, информационных и других систем, где множество сотрудников (учащихся) должны использовать общие данные и обмениваться создаваемыми в процессе работы (обучения). Однако при такой идеологии вся обработка запросов из программ или с терминалов пользовательских ЭВМ выполняется на этих же ЭВМ. Поэтому для реализации даже простого запроса ЭВМ часто должна считывать из файлового сервера и (или) записывать на сервер целые файлы, что ведет к конфликтным ситуациям и перегрузке сети.
Для исключения указанных и некоторых других недостатков была предложена технология "Клиент-Сервер", по которой запросы пользовательских ЭВМ (Клиент) обрабатываются на специальных серверах баз данных (Сервер), а на ЭВМ возвращаются лишь результаты обработки запроса. При этом, естественно, нужен единый язык общения с Сервером и в качестве такого языка выбран SQL. Поэтому все современные версии профессиональных реляционных СУБД (DB2, Oracle, Ingres, Informix, Sybase, Progress, Rdb) и даже нереляционных СУБД (например, Adabas) используют технологию "Клиент-Сервер" и язык SQL. К тому же приходят разработчики СУБД персональных ЭВМ, многие из которых уже сегодня снабжены языком SQL.
Бытует мнение: Поскольку большая часть запросов формулируется на SQL, практически безразлично, что это за СУБД - был бы SQL.
Реализация в SQL концепции операций, ориентированных на табличное представление данных, позволило создать компактный язык с небольшим (менее 30) набором предложений. SQL может использоваться как интерактивный (для выполнения запросов) и как встроенный (для построения прикладных программ). В нем существуют:
В SQL используются следующие основные типы данных, форматы которых могут несколько различаться для разных СУБД:
В некоторых СУБД еще существует тип данных LOGICAL, DOUBLE и ряд других. СУБД INGRES предоставляет пользователю возможность самостоятельного определения новых типов данных, например, плоскостные или пространственные координаты, единицы различных метрик, пяти- или шестидневные недели (рабочая неделя, где сразу после пятницы или субботы следует понедельник), дроби, графика, большие целые числа (что стало очень актуальным для российских банков) и т.п.
Ориентированный на работу с таблицами SQL не имеет достаточных средств для создания сложных прикладных программ. Поэтому в разных СУБД он либо используется вместе с языками программирования высокого уровня (например, такими как Си или Паскаль), либо включен в состав команд специально разработанного языка СУБД (язык систем dBASE, R:BASE и т.п.). Унификация полных языков современных профессиональных СУБД достигается за счет внедрения объектно-ориентированного языка четвертого поколения 4GL. Последний позволяет организовывать циклы, условные предложения, меню, экранные формы, сложные запросы к базам данных с интерфейсом, ориентированным как на алфавитно-цифровые терминалы, так и на оконный графический интерфейс (X-Windows, MS-Windows).
1.1 | Содержание | 1.3
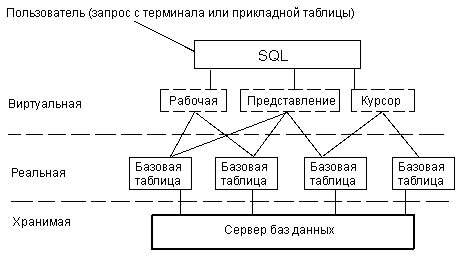
До сих пор понятие "таблица", как правило, связывалось с реальной или базовой таблицей, т.е. c таблицей, для каждой строки которой в действительности имеется некоторый двойник, хранящийся в физической памяти машины (рис.1.2). Однако SQL использует и создает ряд виртуальных (как будто существующих) таблиц: представлений, курсоров и неименованных рабочих таблиц, в которых формируются результаты запросов на получение данных из базовых таблиц и, возможно, представлений. Это таблицы, которые не существуют в базе данных, но как бы существуют с точки зрения пользователя.
Базовые таблицы создаются с помощью предложения CREATE TABLE (создать таблицу), подробное описание которого приведено в главе 5. Здесь же приведем пример предложения для создания описания таблицы Блюда:
Рис. 1.2. База данных в восприятии пользователя
CREATE TABLE Блюда (БЛ SMALLINT, Блюдо CHAR (70), В CHAR (1), Основа CHAR (10), Выход FLOAT, Труд SMALLINT);
Предложение CREAT TABLE специфицирует имя базовой таблицы, которая должна быть создана, имена ее столбцов и типы данных для этих столбцов (а также, возможно, некоторую дополнительную информацию, не иллюстрируемую данным примером). CREAT TABLE - выполняемое предложение. Если его ввести с терминала, система тотчас построит таблицу Блюда, которая сначала будет пустой: она будет содержать только строку заголовков столбцов, но не будет еще содержать никаких строк с данными. Однако можно немедленно приступить к вставке таких строк данных, возможно, с помощью предложения INSERT и создать таблицу, аналогичную таблице Блюда рис.1.1.
Если теперь потребовалось узнать какие овощные блюда может приготовить повар пансионата, то можно набрать на терминале следующий текст запроса:
SELECT БЛ,Блюдо FROM Блюда WHERE Основа = 'Овощи';и мгновенно получить на экране следующий результат его реализации:
| БЛ | Блюдо |
|---|---|
| 1 | Салат летний |
| 3 | Салат витаминный |
| 17 | Морковь с рисом |
| 23 | Помидоры с луком |
Для выполнения этого предложения SELECT (выбрать), подробное описание которого будет дано в главах 2 и 3, СУБД должна сначала сформировать пустую рабочую таблицу, состоящую из столбцов БЛ и Блюдо, тип данных которых должен совпадать с типом данных аналогичных столбцов базовой таблицы Блюда. Затем она должна выбрать из таблицы Блюда все строки, у которых в столбце Основа хранится слово Овощи, выделить из этих строк столбцы БЛ и Блюдо и загрузить укороченные строки в рабочую таблицу. Наконец, СУБД должна выполнить процедуры по организации вывода содержимого рабочей таблицы на экран терминала (при этом если в рабочей таблице содержится более 20-24 строк, она должна использовать процедуры постраничного вывода и т.п.). После выполнения запроса СУБД должна уничтожить рабочую таблицу.
Если, например, надо получить значение калорийности всех овощей, включенных в таблицу Продукты, то можно набрать на терминале запрос
SELECT Продукт, Белки, Жиры, Углев,
((Белки+Углев)*4.1+Жиры*9.3)
FROM Продукты
WHERE Продукт IN ('Морковь','Лук','Помидоры','Зелень');
и получить на экране следующий результат его реализации:
| Продукт | Белки | Жиры | Углев | ((Белки+Углев)*4.1+Жиры*9.3) |
|---|---|---|---|---|
| Морковь | 13. | 1. | 70. | 349.6 |
| Лук | 17. | 0. | 95. | 459.2 |
| Помидоры | 6. | 0. | 42. | 196.8 |
| Зелень | 9. | 0. | 20. | 118.9 |
В последнем столбце этой рабочей таблицы приведены данные о калорийности продуктов, отсутствующие в явном виде в базовой таблице Продукты. Эти данные вычислены по хранимым значениям основных питательных веществ продуктов, помещены в рабочую таблицу и будут существовать до момента смены изображения на экране. Однако если необходимо сохранить эти данные в какой-либо базовой таблице, то существует предложение (INSERT), позволяющее переписать содержимое рабочей таблицы в указанные столбцы базовой таблицы (реляционная операция присваивания).
Часто пользователя не устраивает как способ описания нужного набора выводимых строк, так и результат выполнения запроса, сформированного из данных одной таблицы. Ему хотелось бы уточнить выводимые (запрашиваемые) данные сведениями из других таблиц.
Например, в запросе на получение состава овощных блюд
SELECT БЛ,ПР,Вес FROM Состав WHERE БЛ IN (1,3,17,23);
пришлось перечислять номера этих блюд, так как в таблице Состав нет данных об основных продуктах блюда (они есть в таблице Блюда). Полученный состав овощных блюд (рис.1.3,а) оказался "слепым": в нем и блюда и продукты представлены номерами, а не именами. Удобнее и нагляднее (рис.1.3,б)
| а) | б) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Рис. 1.3. Состав овощных блюд базы данных ПАНСИОН
запрос сформированный по трем таблицам:SELECT Блюдо, Продукт, Вес FROM Состав,Б люда, Продукты WHERE Состав.БЛ = Блюда.БЛ AND Состав.ПР = Продукты.ПР AND Основа = 'Овощи';
В нем для получения рабочей таблицы выполняется естественное соединение [2] таблиц Блюда, Продукты и Состав (условие соединения - равенство значений номеров блюд и значений номеров продуктов). Затем выделяются строки, у которых в столбце Основа хранится слово Овощи, и из этих строк - столбцы Блюдо, Продукт и Вес.
Если пользователи достаточно часто интересуются составом различных блюд, то для упрощения формирования запросов целесообразно создать представление.
Представление - это пустая именованная таблица, определяемая перечнем тех столбцов таблиц и признаками тех их строк, которые хотелось бы в ней увидеть. Представление является как бы "окном" в одну или несколько базовых таблиц. Оно создается с помощью предложения CREATE VIEW (создать представление), подробное описание которого приведено в главе 5. Здесь же приведем пример предложения для создания представления Состав_блюд:
CREATE VIEW Состав_блюд AS SELECT Блюдо, Продукт, Вес FROM Состав,Блюда,Продукты WHERE Состав.БЛ = Блюда.БЛ AND Состав.ПР = Продукты.ПР;
Оно описывает пустую таблицу, в которую при реализации запроса будут загружаться данные из столбцов Блюдо, Продукт и Вес таблиц Блюда, Продукты и Состав, соответственно. Теперь для получения состава овощных блюд можно дать запрос
SELECT Блюдо,Продукт,Вес FROM Состав_блюд WHERE Основа = 'Овощи';
и получить на экране терминала данные, которые представлены на рис. 1.3,б. А для получения состава супа Харчо можно дать запрос
SELECT Блюдо, Продукт, Вес FROM Состав_блюд WHERE Блюдо = 'Суп харчо';
О целесообразности создания представлений будет рассказано ниже, а здесь лишь отметим, что они позволяют повысить уровень логической независимости данных, упростить их восприятие и "скрыть" от некоторых пользователей те или иные данные, например, данные о новых ценах на продукты первой необходимости или из какой рыбы приготавливается "Судак по-польски".
Наконец, еще об одних виртуальных таблицах - курсорах. Курсор - это пустая именованная таблица, определяемая перечнем тех столбцов базовых таблиц и признаками тех их строк, которые хотелось бы в ней увидеть. В чем же различие между курсором и представлением?
Для пользователя представления почти не отличаются от базовых таблиц (есть лишь некоторые ограничения при выполнении различных операций манипулирования данными). Они могут использоваться как в интерактивном режиме, так и в прикладных программах. Курсоры же созданы для процедурной работы с таблицей в прикладных программах. Например, после объявления курсора
DECLARE Блюд_состав CURSOR FOR SELECT Блюдо,Продукт,Вес FROM Состав,Блюда,Продукты WHERE Состав.БЛ = Блюда.БЛ AND Состав.ПР = Продукты.ПР AND Блюдо = 'Суп харчо';
и его активизации (OPEN Блюд_состав) будет создана временная таблица с составом блюда "Суп харчо" и специальным указателем, определяющим в качестве текущей первую строку этой таблицы. С помощью предложения FETCH (выбрать), которое обычно исполняется в программном цикле, можно присвоить определенным переменным значения указанных столбцов этой строки. Одновременно курсор будет передвинут к следующей строке таблицы. После обработки в программе полученных значений переменных выполняется следующее предложение FETCH и т.д. до окончания перебора всех продуктов Харчо.
1.2 | Содержание | 2.1
Все запросы на получение практически любого количества данных из одной или нескольких таблиц выполняются с помощью единственного предложения SELECT. В общем случае результатом реализации предложения SELECT является другая таблица (см. примеры п.1.3). К этой новой (рабочей) таблице может быть снова применена операция SELECT и т.д., т.е. такие операции могут быть вложены друг в друга. Представляет исторический интерес тот факт, что именно возможность включения одного предложения SELECT внутрь другого послужила мотивировкой использования прилагательного "структуризированный" в названии языка SQL.
Предложение SELECT может использоваться как:
В данной и следующей главах будут рассмотрены только две первые функции предложения SELECT, а здесь √ его синтаксис, ограниченный конструкциями, используемыми при реализации этих функций. Здесь (так же как и в других главах книги) в синтаксических конструкциях используются следующие обозначения:
Предложение SELECT (выбрать) имеет следующий формат:
подзапрос [UNION [ALL] подзапрос] ...
[ORDER BY {[таблица.]столбец | номер_элемента_SELECT} [[ASC] | DESC]
[,{[таблица.]столбец | номер_элемента_SELECT} [[ASC] | DESC]] ...;
и позволяет объединить (UNION) а затем упорядочить (ORDER BY) результаты выбора данных, полученных с помощью нескольких "подзапросов". При этом упорядочение можно производить в порядке возрастания - ASC (ASCending) или убывания DESC (DESCending), а по умолчанию принимается ASC.
В этом предложении подзапрос позволяет указать условия для выбора нужных данных и (если требуется) их обработки
и имеет формат
SELECT [[ALL] | DISTINCT]{ * | элемент_SELECT [,элемент_SELECT] ...}
FROM {базовая_таблица | представление} [псевдоним]
[,{базовая_таблица | представление} [псевдоним]] ...
[WHERE фраза]
[GROUP BY фраза [HAVING фраза]];
Элемент_SELECT - это одна из следующих конструкций:
[таблица.]* | значение | SQL_функция | системная_переменная
где значение √ это:
[таблица.]столбец | (выражение) | константа | переменная
Синтаксис выражений имеет вид
( {[ [+] | - ] {значение | функция_СУБД} [ + | - | * | ** ]}... )
а синтаксис SQL_функций √ одна из следующих конструкций:
{SUM|AVG|MIN|MAX|COUNT} ( [[ALL]|DISTINCT][таблица.]столбец )
{SUM|AVG|MIN|MAX|COUNT} ( [ALL] выражение )
COUNT(*)
Фраза WHERE включает набор условий для отбора строк:
WHERE [NOT] WHERE_условие [[AND|OR][NOT] WHERE_условие]...
где WHERE_условие √ одна из следующих конструкций:
значение { = | <> | < | <= | > | >= } { значение | ( подзапрос ) }
значение_1 [NOT] BETWEEN значение_2 AND значение_3
значение [NOT] IN { ( константа [,константа]... ) | ( подзапрос ) }
значение IS [NOT] NULL
[таблица.]столбец [NOT] LIKE 'строка_символов' [ESCAPE 'символ']
EXISTS ( подзапрос )
Кроме традиционных операторов сравнения (= | <> | < | <= | > | >=) в WHERE фразе используются условия BETWEEN (между), LIKE (похоже на), IN (принадлежит), IS NULL (не определено) и EXISTS (существует), которые могут предваряться оператором NOT (не). Критерий отбора строк формируется из одного или нескольких условий, соединенных логическими операторами:
причем существует приоритет AND над OR (сначала выполняются все операции AND и только после этого операции OR). Для получения желаемого результата WHERE условия должны быть введены в правильном порядке, который можно организовать введением скобок.
При обработке условия числа сравниваются алгебраически - отрицательные числа считаются меньшими, чем положительные, независимо от их абсолютной величины. Строки символов сравниваются в соответствии с их представлением в коде, используемом в конкретной СУБД, например, в коде ASCII. Если сравниваются две строки символов, имеющих разные длины, более короткая строка дополняется справа пробелами для того, чтобы они имели одинаковую длину перед осуществлением сравнения.
Наконец, синтаксис фразы GROUP BY имеет вид
GROUP BY [таблица.]столбец [,[таблица.]столбец] ... [HAVING фраза]
GROUP BY инициирует перекомпоновку формируемой таблицы по группам, каждая из которых имеет одинаковое значение в столб-цах, включенных в перечень GROUP BY. Далее к этим группам применяются агрегирующие функции, указанные во фразе SELECT, что приводит к замене всех значений группы на единственное значение (сумма, количество и т.п.).
С помощью фразы HAVING (синтаксис которой почти не отличается от синтаксиса фразы WHERE)
HAVING [NOT] HAVING_условие [[AND|OR][NOT] HAVING_условие]...
можно исключить из результата группы, не удовлетворяющие заданным условиям:
значение { = | <> | < | <= | > | >= } { значение | ( подзапрос )
| SQL_функция }
{значение_1 | SQL_функция_1} [NOT] BETWEEN
{значение_2 | SQL_функция_2} AND {значение_3 | SQL_функция_3}
{значение | SQL_функция} [NOT] IN { ( константа [,константа]... )
| ( подзапрос ) }
{значение | SQL_функция} IS [NOT] NULL
[таблица.]столбец [NOT] LIKE 'строка_символов' [ESCAPE 'символ']
EXISTS ( подзапрос )
1.3 | Содержание | 2.2.1
Запрос выдать название, статус и адрес поставщиков
SELECT Название, Статус, Адрес FROM Поставщики;дает результат, приведенный на рис. 2.1,а.
При необходимости получения полной информации о поставщиках, можно было бы дать запрос
SELECT ПС, Название, Статус, Город, Адрес, Телефон FROM Поставщики;или использовать его более короткую нотацию:
SELECT * FROM Поставщики;
Здесь "звездочка" (*) служит кратким обозначением всех имен полей в таблице, указанной во фразе FROM. При этом порядок вывода полей соответствует порядку, в котором эти поля определялись при создании таблицы.
Еще один пример. Выдать основу всех блюд:
SELECT Основа FROM Блюда;
дает результат, показанный на рис. 2.1,б.
| а) | б) | в) | |||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
Рис. 2.1. Примеры простой выборки
В предыдущем примере был выдан правильный, но не совсем удачный перечень основных продуктов: из него не были исключены дубликаты. Для исключения дубликатов и одновременного упорядочения перечня необходимо дополнить запрос ключевым словом DISTINCT (различный, различные), как показано в следующем примере:
SELECT DISTINCT Основа FROM Блюда;
Результат приведен на рис. 2.1,в.
2.1 | Содержание | 2.2.3
Из синтаксиса фразы SELECT (п.2.1) видно, что в ней может содержаться не только перечень столбцов таблицы или символ *, но и выражения.
Например, если нужно получить значение калорийности всех продуктов, то можно учесть, что при окислении 1 г углеводов или белков в организме освобождается в среднем 4.1 ккал, а при окислении 1 г жиров - 9.3 ккал, и выдать запрос:
SELECT Продукт, ((Белки+Углев)*4.1+Жиры*9.3) FROM Продукты;
результат которого приведен на рис. 2.2,а.
| а) | б) | в) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
Рис. 2.2. Примеры запросов с вычисляемыми полями
Фраза SELECT может включать не только выражения, но и отдельные числовые или текстовые константы. Следует отметить, что текстовые константы должны заключаться в апострофы ('). На рис. 2.2,б приведен результат запроса:
SELECT Продукт, 'Калорий =', ((Белки+Углев)*4.1+Жиры *9.3) FROM Продукты;
А что произойдет, если какой-либо член выражения не определен, т.е. имеет значение NULL и каким образом появилось такое значение?
Если при загрузке строк таблицы в какой-либо из вводимых строк отсутствует значение для какого-либо столбца, то СУБД введет в такое поле NULL-значение. NULL-значение "придумано" для того, чтобы представить единым образом "неизвестные значения" для любых типов данных. Действительно, так как при вводе данных в столбец или их изменении СУБД запрещает ввод значений не соответствующих описанию данных этого столбца, то, например, нельзя использовать пробел для отсутствующего значения числа. Нельзя для этих целей использовать и ноль: нет месяца или дня недели равного нулю, да и для чисел ноль не может рассматриваться как неизвестное значение в одном месте и как известное - в другом. При выводе же NULL-значения на экран или печатающее устройство его код воспроизводится каким-либо специально заданным символом или набором символов: например, пробелом (если его нельзя перепутать с текстовым значением пробела) или сочетанием -0-.
С помощью специальной команды можно установить в СУБД один из режимов представления NULL-значений при выполнении числовых расчетов: запрет или разрешение замены NULL-значения нулем. В первом случае любое арифметическое выражение, содержащее неопределенный операнд, будет также иметь неопределенное значение. Во втором случае результат вычислений будет иметь численное значение (если это значение попадает в диапазон представления соответствующего типа данных).
Например, при выполнении запроса
SELECT ПР, Цена, К_во, (Цена * К_во) FROM Поставки;
и разных "настройках" СУБД могут быть получены разные результаты:
|
|
2.2.2 | Содержание | 2.3.1
В синтаксисе фразы WHERE (п.2.1) показано, что для отбора нужных строк таблицы можно использовать операторы сравнения = (равно), <> (не равно), < (меньше), <= (меньше или равно), > (больше), >= (больше или равно), которые могут предваряться оператором NOT, создавая, например, отношения "не меньше" и "не больше".
Так, для получения перечня продуктов, практически не содержащих углеводов, можно сформировать запрос
SELECT Продукт, Белки, Жиры, Углев, K, Ca, Na, B2, PP, C FROM Продукты WHERE Углев = 0;
и получить:
| Продукт | Белки | Жиры | Углев | K | Ca | Na | B2 | PP | C |
|---|---|---|---|---|---|---|---|---|---|
| Говядина | 189. | 124. | 0. | 3150 | 90 | 600 | 1.5 | 28. | 0 |
| Судак | 190. | 80. | 0. | 1870 | 270 0 | 1.1 | 10. | 30 |
Возможность использования нескольких условий, соединенных логическими операторами AND, OR, AND NOT и OR NOT, позволяет осуществить более детальный отбор строк. Так, для получения перечня продуктов, практически не содержащих углеводов и натрия, можно сформировать запрос:
SELECT Продукт, Белки, Жиры, Углев, K, Ca, Na, B2, PP, C FROM Продукты WHERE Углев = 0 AND Na = 0;
Результат запроса имеет вид
| Продукт | Белки | Жиры | Углев | K | Ca | Na | B2 | PP | C |
|---|---|---|---|---|---|---|---|---|---|
| Судак | 190. | 80. | 0. | 1870 | 270 | 0 | 1.1 | 10. | 30 |
Добавим к этому запросу еще одно условие
SELECT Продукт, Белки, Жиры, Углев, K, Ca, Na, B2, PP, C FROM Продукты WHERE Углев = 0 AND Na = 0 AND Продукт <> 'Судак';
и получим на экране сообщение "No rows exist or satisfy the specified clause" или аналогичное (в зависимости от вкусов разработчиков разных СУБД), информирующее об отсутствии строк, удовлетворяющих заданному(ым) условию(ям).
2.2.3 | Содержание | 2.3.2
С помощью BETWEEN ... AND ... (находится в интервале от ... до ...) можно отобрать строки, в которых значение какого-либо столбца находятся в заданном диапазоне.
Например, выдать перечень продуктов, в которых значение содержания белка находится в диапазоне от 10 до 50:| Результат: | ||
|---|---|---|
SELECT Продукт, Белки FROM Продукты WHERE Белки BETWEEN 10 AND 50; |
||
| Продукт | Белки | |
| Майонез | 31. | |
| Сметана | 26. | |
| Молоко | 28. | |
| Морковь | 13. | |
| Лук | 17. | |
Можно задать и NOT BETWEEN (не принадлежит диапазону между), например:
| Результат: | ||
|---|---|---|
SELECT Продукт, Белки, Жиры FROM Продукты WHERE Белки NOT BETWEEN 10 AND 50 AND Жиры > 100; |
||
| Продукт | Белки | Жиры |
| Говядина | 189. | 124. |
| Масло | 60. | 825. |
| Яйца | 127. | 115. |
BETWEEN особенно удобен при работе с данными, задаваемыми интервалами, начало и конец которых расположен в разных столбцах.
Для примера воспользуемся таблицей "минимальных окладов" (табл. 2.1), величина которых непосредственно связана со студенческой стипендией. В этой таблице для текущего значения минимального оклада установлена запредельная дата окончания 9 сентября 9999 года.
Таблица 2.1
Минимальные оклады
| Миноклад | Начало | Конец |
|---|---|---|
| 2250 | 01-01-1993 | 31-03-1993 |
| 4275 | 01-04-1993 | 30-06-1993 |
| 7740 | 01-07-1993 | 30-11-1993 |
| 14620 | 01-12-1993 | 30-06-1994 |
| 20500 | 01-07-1994 | 09-09-9999 |
Если, например, потребовалось узнать, какие изменения минимальных окладов производились в 1993/94 учебном году, то можно выдать запрос
SELECT Начало, Миноклад FROM Миноклады WHERE Начало BETWEEN '1-9-1993' AND '31-8-1994'и получить результат:
| Начало | Миноклад |
|---|---|
| 01-12-1993 | 14620 |
| 01-07-1994 | 20500 |
Отметим, что при формировании запросов значения дат следует заключать в апострофы, чтобы СУБД не путала их с выражениями и не пыталась вычитать из 31 значение 8, а затем 1994.
Для выявления всех значений минимальных окладов, которые существовали в 1993/94 учебном году, можно сформировать запрос
SELECT * FROM Миноклады WHERE Начало BETWEEN '1-9-1993' AND '31-8-1994' OR Конец BETWEEN '1-9-1993' AND '31-8-1994'
| Миноклад | Начало | Конец |
|---|---|---|
| 7740 | 01/07/1993 | 30/11/1993 |
| 14620 | 01/12/1993 | 30/06/1994 |
| 20500 | 01/07/1994 | 09/09/9999 |
Наконец, для получения минимального оклада на 15-5-1994:
| Результат: | ||
|---|---|---|
SELECT Миноклад FROM Миноклады WHERE '15-05-1994' BETWEEN Начало AND Конец |
||
| Миноклад | ||
| 14620 | ||
2.3.1 | Содержание | 2.3.3
Выдать сведения о блюдах на основе яиц, крупы и овощей
SELECT * FROM Блюда WHERE Основа IN (Яйца Крупа Овощи);
Результат:
| БЛ | Блюдо | В | Основа | Выход | Труд |
|---|---|---|---|---|---|
| 1 | Салат летний | З | Овощи | 200. | 3 |
| 3 | Салат витаминный | З | Овощи | 200. | 4 |
| 16 | Драчена | Г | Яйца | 180. | 4 |
| 17 | Морковь с рисом | Г | Овощи | 260. | 3 |
| 19 | Омлет с луком | Г | Яйца | 200. | 5 |
| 20 | Каша рисовая | Г | Крупа | 210. | 4 |
| 21 | Пудинг рисовый | Г | Крупа | 160. | 6 |
| 23 | Помидоры с луком | Г | Овощи | 260. | 4 |
Рассмотренная форма IN является в действительности просто краткой записью последовательности отдельных сравнений, соединенных операторами OR. Предыдущее предложение эквивалентно такому:
SELECT * FROM Блюда WHERE Основа=Яйца OR Основа=Крупа OR Основа=Овощи;
Можно задать и NOT IN (не принадлежит), а также возможность использования IN (NOT IN) с подзапросом (см. главу 3).
2.3.2 | Содержание | 2.3.4
Выдать перечень салатов
| Результат: | ||
|---|---|---|
SELECT Блюдо FROM Блюда WHERE Блюдо LIKE 'Салат%'; |
||
| Блюдо | ||
| Салат летний | ||
| Салат мясной | Салат витаминный | |
| Салат рыбный | ||
Обычная форма "имя_столбца LIKE текстовая_константа" для столбца текстового типа позволяет отыскать все значения указанного столбца, соответствующие образцу, заданному "текстовой_константой". Символы этой константы интерпретируются следующим образом:
Следовательно, в приведенном примере SELECT будет осуществлять выборку записей из таблицы Блюда, для которых значение в столбце Блюдо начинается сочетанием 'Салат' и содержит любую последовательность из нуля или более символов, следующих за сочетанием 'Салат'. Если бы среди блюд были "Луковый салат", "Фруктовый салат" и т.п., то они не были бы найдены. Для их отыскания надо изменить фразу WHERE:
WHERE Блюдо LIKE '%салат%'
или при отсутствии различий между малыми и большими буквами (такую настройку допускают некоторые СУБД):
WHERE Блюдо LIKE '%Салат%'
Это позволит отыскать все салаты.
2.3.3 | Содержание | 2.3.5
Как было рассказано в п.2.2.3, если при загрузке данных не введено значение в какое-либо поле таблицы, то СУБД поместит в него NULL-значение. Аналогичное значение можно ввести в поле таблицы, выполняя операцию изменения данных. Так, при отсутствии сведений о наличии у поставщиков судака и моркови в столбцы Цена и К_во соответствующих строк таблицы Поставки вводится NULL и там будет храниться код NULL-значения, а не 0, 0. или пробел. (Отметим, что в распечатке таблицы Поставки рис.1.1 в этих местах расположен пробел, установленный в СУБД для представления NULL-значения при выводе на печать).
В этом случае для выявления названий продуктов, отсутствующих в кладовой, шеф-повар может дать запрос
| Результат: | ПР | |
|---|---|---|
SELECT DISTINCT ПР FROM Наличие WHERE К_во IS NULL; |
2
9 | |
Естественно, что для выявления продуктов, существующих в кладовой, следует дать запрос
SELECT DISTINCT ПР FROM Наличие WHERE К_во IS NOT NULL;
Использование условий
столбец IS NULL и столбец IS NOT NULL
вместо, например,
столбец = NULL и столбец <> NULL
связано с тем, что ничто - и даже само NULL-значение - не считается равным другому NULL-значению. (Несмотря на это, два неопределенных значения рассматриваются, однако, как дубликаты друг друга при исключении дубликатов, и предложение SELECT DISTINCT даст в результате не более одного NULL-значения.)
2.3.4 | Содержание | 2.4
Синтаксис фразы упорядочения был дан в п. 2.1. Простейший вариант этой фразы - упорядочение строк результата по значению одного из столбцов с указанием порядка сортировки или без такого указания. (По умолчанию строки будут сортироваться в порядке возрастания значений в указанном столбце.)
Например, выдать перечень продуктов и содержание в них основных веществ в порядке убывания содержания белка
| Результат: | ||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||||||||||||||||||||||
При включении в список ORDER BY нескольких столбцов СУБД сортирует строки результата по значениям первого столбца списка пока не появится несколько строк с одинаковыми значениями данных в этом столбце. Такие строки сортируются по значениям следующего столбца из списка ORDER BY и т.д.
Например, выдать содержимое таблицы Блюда, отсортировав ее строки по видам блюд и основе:
| Результат: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Кроме того, в список ORDER BY можно включать не только имя столбца, а его порядковую позицию в перечне SELECT. Благодаря этому возможно упорядочение результатов на основе вычисляемых столбцов, не имеющих имен.
Например, запрос
SELECT Продукт, ((Белки+Углев)*4.1+Жиры*9.3) FROM Продукты ORDER BY 2;
позволит получить список продуктов, показанный на рис.2.2,в √ переупорядоченный по возрастанию значений калорийности список рис.2.2,а.
2.3.5 | Содержание | 2.5.1
В SQL существует ряд специальных стандартных функций (SQL-функций). Кроме специального случая COUNT(*) каждая из этих функций оперирует совокупностью значений столбца некоторой таблицы и создает единственное значение, определяемое так:
Для функций SUM и AVG рассматриваемый столбец должен содержать числовые значения.
Следует отметить, что здесь столбец - это столбец виртуальной таблицы, в которой могут содержаться данные не только из столбца базовой таблицы, но и данные, полученные путем функционального преобразования и (или) связывания символами арифметических операций значений из одного или нескольких столбцов. При этом выражение, определяющее столбец такой таблицы, может быть сколь угодно сложным, но не должно содержать SQL-функций (вложенность SQL-функций не допускается). Однако из SQL-функций можно составлять любые выражения.
Аргументу всех функций, кроме COUNT(*), может предшествовать ключевое слово DISTINCT (различный), указывающее, что избыточные дублирующие значения должны быть исключены перед тем, как будет применяться функция. Специальная же функция COUNT(*) служит для подсчета всех без исключения строк в таблице (включая дубликаты).
2.4 | Содержание | 2.5.2
Если не используется фраза GROUP BY, то в перечень элементов_SELECT можно включать лишь SQL-функции или выражения, содержащие такие функции. Другими словами, нельзя иметь в списке столбцы, не являющихся аргументами SQL-функций.
Например, выдать данные о массе лука (ПР=10), проданного поставщиками, и указать количество этих поставщиков:
| Результат: | ||
|---|---|---|
SELECT SUM(К_во),COUNT(К_во) FROM Поставки WHERE ПР = 10; |
||
| SUM(К_во) | COUNT(К_во) | |
| 220 | 2 | |
Если бы для вывода в результат еще и номера продукта был сформирован запрос
SELECT ПР,SUM(К_во),COUNT(К_во) FROM Поставки WHERE ПР = 10;
то было бы получено сообщение об ошибке. Это связано с тем, что SQL-функция создает единственное значение из множества значений столбца-аргумента, а для "свободного" столбца должно быть выдано все множество его значений. Без специального указания (оно задается фразой GROUP BY) SQL не будет выяснять, одинаковы значения этого множества (как в данном примере, где ПР=10) или различны (как было бы при отсутствии WHERE фразы). Поэтому подобный запрос отвергается системой.
Правда, никто не запрещает дать запрос
SELECT 'Кол-во лука =',SUM(К_во),COUNT(К_во) FROM Поставки WHERE ПР = 10;
| Результат: | ||
|---|---|---|
| 'Кол-во лука =' | SUM(К_во) | COUNT(К_во) |
| Кол-во лука = | 220 | 2 |
Отметим также, что в столбце-аргументе перед применением любой функции, кроме COUNT(*), исключаются все неопределенные значения. Если оказывается, что аргумент - пустое множество, функция COUNT принимает значение 0, а остальные - NULL.
Например, для получения суммы цен, средней цены, количества поставляемых продуктов и количества разных цен продуктов, проданных коопторгом УРОЖАЙ (ПС=5), а также для получения количества продуктов, которые могут поставляться этим коопторгом, можно дать запрос
SELECT SUM(Цена),AVG(Цена),COUNT(Цена), COUNT(DISTINCT Цена),COUNT(*) FROM Поставки WHERE ПС = 5;
и получить
| SUM(Цена) | AVG(Цена) | COUNT(Цена) | COUNT(DISTINCT Цена) | COUNT |
|---|---|---|---|---|
| 6.2 | 1.24 | 5 | 4 | 7 |
В другом примере, где надо узнать "Сколько поставлено моркови и сколько поставщиков ее поставляют?":
SELECT SUM(К_во),COUNT(К_во) FROM Поставки WHER ПР = 2;
будет получен ответ:
| SUM(К_во) | COUNT (К_во) |
|---|---|
| -0- | 0 |
Наконец, попробуем получить сумму массы поставленного лука с его средней ценой ("Сапоги с яичницей"):
| Результат: | |
|---|---|
SELECT (SUM(К_во) +AVG(Цена)) FROM Поставки WHERE ПР = 10; |
|
| SUM(К_во)+AVG(Цена) | |
| 220.6 |
2.5.1 | Содержание | 2.5.3
Мы показали, как можно вычислить массу определенного продукта, поставляемого поставщиками. Предположим, что теперь требуется вычислить общую массу каждого из продуктов, поставляемых в настоящее время поставщиками. Это можно легко сделать с помощью предложения
SELECT ПР, SUM(К_во) FROM Поставки GROUP BY ПР;
Результат показан на рис. 2.3,а.
| а) | б) | в) | г) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 2.3. Иллюстрации к фразе GROUP BY
Фраза GROUP BY (группировать по) инициирует перекомпоновку указанной во FROM таблицы по группам, каждая из которых имеет одинаковые значения в столбце, указанном в GROUP BY. В рассматриваемом примере строки таблицы Поставки группируются так, что в одной группе содержатся все строки для продукта с ПР = 1, в другой √ для продукта с ПР = 2 и т.д. (см. рис. 2.3.б). Далее к каждой группе применяется фраза SELECT. Каждое выражение в этой фразе должно принимать единственное значение для группы, т.е. оно может быть либо значением столбца, указанного в GROUP BY, либо арифметическим выражением, включающим это значение, либо константой, либо одной из SQL-функций, которая оперирует всеми значениями столбца в группе и сводит эти значения к единственному значению (например, к сумме).
Отметим, что фраза GROUP BY не предполагает ORDER BY. Чтобы гарантировать упорядочение по ПР результата рассматриваемого примера (рис. 2.3,в) следует дать запрос
SELECT ПР, SUM(К_во) FROM Поставки GROUP BY ПР ORDER BY ПР;
Наконец, отметим, что строки таблицы можно группировать по любой комбинации ее столбцов. Так, по запросу
SELECT Т, БЛ, COUNT(БЛ) FROM Заказ GROUP BY Т, БЛ;
можно узнать коды и количество порций блюд, заказанных отдыхающими пансионата (32 человека) на каждую из трапез следующего дня:
| Т | БЛ | COUNT(БЛ) |
|---|---|---|
| 1 | 3 | 18 |
| 1 | 6 | 14 |
| 1 | 19 | 17 |
| 1 | 21 | 15 |
| ... | ||
Если в запросе используются фразы WHERE и GROUP BY, то строки, не удовлетворяющие фразе WHERE, исключаются до выполнения группирования.
Например, выдать для каждого продукта его код и общий объем возможных поставок, учитывая временную недееспособность поставщика с ПС=2:
SELECT ПР, SUM(К_во) FROM Поставки WHERE ПС <> 2 GROUP BY ПР;
Результат, приведенный на рис. 2.3,г, отличается от результата (рис. 2.3,а) аналогичного запроса для всех поставщиков объемом поставок продуктов с кодами 15, 5 и 6.
2.5.2 | Содержание | 2.5.4
Фраза HAVING (рис.2.3) играет такую же роль для групп, что и фраза WHERE для строк: она используется для исключения групп, точно так же, как WHERE используется для исключения строк. Эта фраза включается в предложение лишь при наличии фразы GROUP BY, а выражение в HAVING должно принимать единственное значение для группы.
Например, выдать коды продуктов, поставляемых более чем двумя поставщиками:
SELECT FROM Поставки GROUP BY ПС HAVING COUNT(*) > 2; |
Результат: | ПР |
|---|---|---|
| 9 | ||
| 11 | ||
| 12 |
В п.3.6 можно познакомиться с более содержательным примером использования этой фразы.
2.5.3 | Содержание | 3.1
Затрагивая вопросы проектирования баз данных [2], мы выяснили, что базы данных - это множество взаимосвязанных сущностей или отношений (таблиц) в терминологии реляционных СУБД. При проектировании стремятся создавать таблицы, в каждой из которых содержалась бы информация об одном и только об одном типе сущностей. Это облегчает модификацию базы данных и поддержание ее целостности. Но такой подход тяжело усваивается начинающими проектантами, которые пытаются привязать проект к будущим приложениям и так организовать таблицы, чтобы в каждой из них хранилось все необходимое для реализации возможных запросов. Типичен вопрос: как же получить сведения о том, где купить продукты для приготовления того или иного блюда и определить его калорийность и стоимость, если нужные данные "рассыпаны" по семи различным таблицам? Не лучше ли иметь одну большую таблицу, содержащую все сведения базы данных ПАНСИОН ?
Даже при отсутствии средств одновременного доступа ко многим таблицам нежелателен проект, в котором информация о многих типах сущностей перемешана в одной таблице. SQL же обладает великолепным механизмом для одновременной или последовательной обработки данных из нескольких взаимосвязанных таблиц. В нем реализованы возможности "соединять" или "объединять" несколько таблиц и так называемые "вложенные подзапросы". Например, чтобы получить перечень поставщиков продуктов, необходимых для приготовления Сырников, возможен запрос
SELECT Продукт, Цена, Название, Статус FROM Продукты, Состав, Блюда, Поставки, Поставщики WHERE Продукты.ПР = Состав.ПР AND Состав.БЛ = Блюда.БЛ AND Поставки.ПР = Состав.ПР AND Поставки.ПС = Поставщики.ПС AND Блюдо = 'Сырники' AND Цена IS NOT NULL;
| Продукт | Цена | Название | Статус |
|---|---|---|---|
| Яйца | 1.8 | ПОРТОС | кооператив |
| Яйца | 2. | КОРЮШКА | кооператив |
| Сметана | 3.6 | ПОРТОС | кооператив |
| Сметана | 2.2 | ОГУРЕЧИК | ферма |
| Творог | 1. | ОГУРЕЧИК | ферма |
| Мука | 0.5 | УРОЖАЙ | коопторг |
| Сахар | 0.94 | ТУЛЬСКИЙ | универсам |
| Сахар | 1. | УРОЖАЙ | коопторг |
Он получен следующим образом: СУБД последовательно формирует строки декартова произведения таблиц, перечисленных во фразе FROM, проверяет, удовлетворяют ли данные сформированной строки условиям фразы WHERE, и если удовлетворяют, то включает в ответ на запрос те ее поля, которые перечислены во фразе SELECT.
Следует подчеркнуть, что в SELECT и WHERE (во избежание двусмысленности) ссылки на все (*) или отдельные столбцы могут (а иногда и должны) уточняться именем соответствующей таблицы, например, Поставки.ПС, Поставщики.ПС, Меню.*, Состав.БЛ, Блюда.* и т.п.
Очевидно, что с помощью соединения несложно сформировать запрос на обработку данных из нескольких таблиц. Кроме того, в такой запрос можно включить любые части предложения SELECT, рассмотренные в главе 2 (выражения с использованием функций, группирование с отбором указанных групп и упорядочением полученного результата). Следовательно, соединения позволяют обрабатывать множество взаимосвязанных таблиц как единую таблицу, в которой перемешана информация о многих типах сущностей. Поэтому начинающий проектант базы данных может спокойно создавать маленькие нормализованные таблицы, так как он всегда может получить из них любую "большую" таблицу.
Кроме механизма соединений в SQL есть механизм вложенных подзапросов, позволяющий объединить несколько простых запросов в едином предложении SELECT. Иными словами, вложенный подзапрос - это уже знакомый нам подзапрос (с небольшими огра-ничениями), который вложен в WHERE фразу другого вложенного подзапроса или WHERE фразу основного запроса.
Для иллюстрации вложенного подзапроса вернемся к предыдущему примеру и попробуем получить перечень тех поставщиков продуктов для Сырников, которые поставляют нужные продукты за минимальную цену.
SELECT Продукт, Цена, Название, Статус FROM Продукты, Состав, Блюда, Поставки, Поставщики WHERE Продукты.ПР = Состав.ПР AND Состав.БЛ = Блюда.БЛ AND Поставки.ПР = Состав.ПР AND Поставки.ПС = Поставщики.ПС AND Блюдо = 'Сырники' AND Цена = ( SELECT MIN(Цена) FROM Поставки X WHERE X.ПР = Поставки.ПР );
Результат запроса имеет вид
| Продукт | Цена | Название | Статус |
|---|---|---|---|
| Яйца | 1.8 | ПОРТОС | кооператив |
| Сахар | 0.94 | ТУЛЬСКИЙ | универсам |
| Мука | 0.5 | УРОЖАЙ | коопторг |
| Сметана | 2.2 | ОГУРЕЧИК | ферма |
| Творог | 1. | ОГУРЕЧИК | ферма |
Здесь с помощью подзапроса, размещенного в трех последних строках запроса, описывается процесс определения минимальной цены каждого продукта для Сырников и поиск поставщика, предлагающего этот продукт за такую цену. Механизм реализации подзапросов будет подробно описан в п.3.3. Там же будет рассмотрено, как и для чего вводится псевдоним X для имени таблицы Поставки.
2.5.4 | Содержание | 3.2.1
В литературе [2] показано, что соединения - это подмножества декартова произведения. Так как декартово произведение n таблиц - это таблица, содержащая все возможные строки r, такие, что r является сцеплением какой-либо строки из первой таблицы, строки из второй таблицы, ... и строки из n-й таблицы (а мы уже научились выделять с помощью SELECT любое подмножество реляционной таблицы), то осталось лишь выяснить, можно ли с помощью SELECT получить декартово произведение. Для получения декартова произведения нескольких таблиц надо указать во фразе FROM перечень перемножаемых таблиц, а во фразе SELECT √ все их столбцы.
Так, для получения декартова произведения Вид_блюд и Трапезы надо выдать запрос
SELECT Вид_блюд.*, Трапезы.* FROM Вид_блюд, Трапезы;
Получим таблицу, содержащую 5 х 3 = 15 строк:
| В | Вид | Т | Трапеза |
|---|---|---|---|
| З | Закуска | 1 | Завтрак |
| З | Закуска | 2 | Обед |
| З | Закуска | 3 | Ужин |
| С | Суп | 1 | Завтрак |
| С | Суп | 2 | Обед |
| С | Суп | 3 | Ужин |
| Г | Горячее | 1 | Завтрак |
| Г | Горячее | 2 | Обед |
| Г | Горячее | 3 | Ужин |
| Д | Десерт | 1 | Завтрак |
| Д | Десерт | 2 | Обед |
| Д | Десерт | 3 | Ужин |
| Н | Напиток | 1 | Завтрак |
| Н | Напиток | 2 | Обед |
| Н | Напиток | 3 | Ужин |
В другом примере, где перемножаются таблицы Меню, Трапезы, Вид_блюд, Блюда:
SELECT Меню.*, Трапезы.*, Вид_блюд.*, Блюда.* FROM Меню, Трапезы, Вид_блюд, Блюда;
образуется таблица (рис 3.1), содержащая 21 х 3 х 5 х 33 = 10395 строк.
Из первых 39 строк этой таблицы лишь две актуальных (отмечены "*"): в них совпадают номера блюд таблиц Меню и Блюда. В остальных √ полная чепуха: к закускам отнесены супы и напитки, на завтрак предлагается незапланированный суп и т.д.
3.1 | Содержание | 3.2.2
Если из декартова произведения убрать ненужные строки и столбцы, то можно получить актуальные таблицы, соответствующие любому из соединений.
| Меню | Трапезы | Вид_блюд | Блюда | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Т | В | БЛ | Т | Трапеза | В | Вид | БЛ | Блюдо | В | Основа | Выход | Труд |
| 1 | З | 3 | 1 | Завтрак | З | Закуска | 1 | Салат летний | З | Овощи | 200. | 3 |
| 1 | З | 3 | 1 | Завтрак | З | Закуска | 2 | Салат мясной | З | Мясо | 200. | 4 |
| 1 | З | 3 | 1 | Завтрак | З | Закуска | 3 | Салат витаминный | З | Овощи | 200. | 4 * |
| . . . | ||||||||||||
| 1 | З | 3 | 1 | Завтрак | З | Закуска | 12 | Суп молочный | С | Молоко | 500. | 3 |
| 1 | З | 3 | 1 | Завтрак | З | Закуска | 13 | Бастурма | Г | Мясо | 300. | 5 |
| . . . | ||||||||||||
| 1 | З | 3 | 1 | Завтрак | З | Закуска | 32 | Кофе черный | Н | Кофе | 100. | 1 |
| 1 | З | 3 | 1 | Завтрак | З | Закуска | 33 | Кофе на молоке | Н | Кофе | 200. | 2 |
| 1 | З | 6 | 1 | Завтрак | З | Закуска | 1 | Салат летний | З | Овощи | 200. | 3 |
| 1 | З | 6 | 1 | Завтрак | З | Закуска | 2 | Салат мясной | З | Мясо | 200. | 4 |
| 1 | З | 6 | 1 | Завтрак | З | Закуска | 3 | Салат витаминный | З | Овощи | 200. | 4 |
| 1 | З | 6 | 1 | Завтрак | З | Закуска | 4 | Салат рыбный | З | Рыба | 200. | 4 |
| 1 | З | 6 | 1 | Завтрак | З | Закуска | 5 | Паштет из рыбы | З | Рыба | 120. | 5 |
| 1 | З | 6 | 1 | Завтрак | З | Закуска | 6 | Мясо с гарниром | З | Мясо | 250. | 3 * |
| . . . | ||||||||||||
Рис. 3.1. Иллюстрация декартова произведения
Очевидно, что отбор актуальных строк обеспечивается вводом в запрос WHERE фразы, в которой устанавливается соответствие между:
Такой скорректированный запрос
SELECT Меню.*, Трапезы.*, Вид_блюд.*, Блюда.* FROM Меню, Трапезы, Вид_блюд, Блюда WHERE Меню.Т = Трапезы.Т AND Меню.В = Вид_блюд.В AND Меню.БЛ = Блюда.БЛ;
позволит получить эквисоединение таблиц Меню, Трапезы, Вид_блюд и Блюда:
| Т | В | БЛ | Т | Трапеза | В | Вид | БЛ | Блюдо | В | Основа | Выход | Труд |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | З | 3 | 1 | Завтрак | З | Закуска | 3 | Салат витаминный | З | Овощи | 200. | 4 |
| 1 | З | 6 | 1 | Завтрак | З | Закуска | 6 | Мясо с гарниром | З | Мясо | 250. | 3 |
| 1 | Г | 19 | 1 | Завтрак | Г | Горячее | 19 | Омлет с луком | Г | Яйца | 200. | 5 |
| . . . | ||||||||||||
| 3 | Г | 16 | 3 | Ужин | Г | Горячее | 16 | Драчена | Г | Яйца | 180. | 4 |
| 3 | Н | 30 | 3 | Ужин | Н | Напиток | 30 | Компот | Н | Фрукты | 200. | 2 |
| 3 | Н | 31 | 3 | Ужин | Н | Напиток | 31 | Молочный напиток | Н | Молоко | 200. | 2 |
3.2.1 | Содержание | 3.2.3
Легко заметить, что в эквисоединение таблиц вошли дубликаты столбцов, по которым проводилось соединение (Т, В и БЛ). Для исключения этих дубликатов можно создать естественное соединение тех же таблиц:
SELECT Т, В, БЛ, Трапеза, Вид, Блюдо, Основа, Выход, Труд FROM Меню, Трапезы, Вид_блюд, Блюда WHERE Меню.Т = Трапезы.Т AND Меню.В = Вид_блюд.В AND Меню.БЛ = Блюда.БЛ;
Реализация естественного соединения таблиц имеет вид
| Т | В | БЛ | Трапеза | Вид | Блюдо | Основа | Выход | Труд |
|---|---|---|---|---|---|---|---|---|
| 1 | З | 3 | Завтрак | Закуска | Салат витаминный | Овощи | 200. | 4 |
| 1 | З | 6 | Завтрак | Закуска | Мясо с гарниром | Мясо | 250. | 3 |
| 1 | Г | 19 | Завтрак | Горячее | Омлет с луком | Яйца | 200. | 5 |
| ... | ||||||||
| 3 | Г | 16 | Ужин | Горячее | Драчена | Яйца | 180. | 4 |
| 3 | Н | 30 | Ужин | Напиток | Компот | Фрукты | 200. | 2 |
| 3 | Н | 31 | Ужин | Напиток | Молочный напиток | Молоко | 200. | 2 |
3.2.2 | Содержание | 3.2.4
Для исключения всех столбцов, по которым проводится соединение таблиц, надо создать композицию
SELECT Трапеза, Вид, Блюдо, Основа, Выход, Труд FROM Меню, Трапезы, Вид_блюд, Блюда WHERE Меню.Т = Трапезы.Т AND Меню.В = Вид_блюд.В AND Меню.БЛ = Блюда.БЛ;
имеющую вид
| Трапеза | Блюдо | Вид | Основа | Выход | Труд |
|---|---|---|---|---|---|
| Завтрак | Салат витаминный | Закуска | Овощи | 200. | 4 |
| Завтрак | Мясо с гарниром | Закуска | Мясо | 250. | 3 |
| Завтрак | Омлет с луком | Горячее | Яйца | 200. | 5 |
| . . . | |||||
| Ужин | Драчена | Горячее | Яйца | 180. | 4 |
| Ужин | Компот | Напиток | Фрукты | 200. | 2 |
| Ужин | Молочный напиток | Напиток | Молоко | 200. | 2 |
3.2.3 | Содержание | 3.2.5
В базе данных ПАНСИОН трудно подобрать несложный пример, иллюстрирующий тета-соединение таблиц. Поэтому сконструируем такой надуманный запрос:
SELECT Вид_блюд.*, Трапезы.* FROM Вид_блюд, Трапезы WHERE Вид > Трапеза;
позволяющий выбрать из полученного в п.3.2.1 декартова произведения таблиц Вид_блюд и Трапезы лишь те строки, в которых значение трапезы "меньше" (по алфавиту) значения вида блюда:
| В | Вид | Т | Трапеза |
|---|---|---|---|
| З | Закуска | 1 | Завтрак |
| С | Суп | 1 | Завтрак |
| С | Суп | 2 | Обед |
| Н | Напиток | 1 | Завтрак |
3.2.4 | Содержание | 3.2.6
При формировании соединения создается рабочая таблица, к которой применимы все операции, рассмотренные в главе 2: отбор нужных строк соединения (WHERE фраза), упорядочение получаемого результата (ORDER BY фраза) и агрегатирование данных (SQL-функции и GROUP BY фраза).
Например, для получения перечня блюд, предлагаемых в меню на завтрак, можно сформировать запрос на основе композиции (п. 3.2.4):
SELECT Вид, Блюдо, Основа, Выход, 'Номер -', БЛ FROM Меню, Трапезы, Вид_блюд, Блюда WHERE Меню.Т = Трапезы.Т AND Меню.В = Вид_блюд.В AND Меню.БЛ = Блюда.БЛ AND Трапеза = ▓Завтрак▓;
Получим
| Вид | Блюдо | Основа | Выход | 'Номер -' | БЛ |
|---|---|---|---|---|---|
| Закуска | Салат витаминный | Овощи | 200. | Номер - | 3 |
| Закуска | Мясо с гарниром | Мясо | 250. | Номер - | 6 |
| Горячее | Омлет с луком | Яйца | 200. | Номер - | 19 |
| Горячее | Пудинг рисовый | Крупа | 160. | Номер - | 21 |
| Напиток | Молочный напиток | Молоко | 200. | Номер - | 31 |
| Напиток | Кофе черный | Кофе | 100. | Номер - | 32 |
В п.3.6 можно познакомиться с достаточно полным примером соединения таблиц с различными дополнительными фразами.
3.2.5 | Содержание | 3.2.7
В ряде приложений возникает необходимость одновременной обработки данных какой-либо таблицы и одной или нескольких ее копий, создаваемых на время выполнения запроса.
Например, при создании списков студентов (таблица Студенты) возможен повторный ввод данных о каком-либо студенте с присвоением ему второго номера зачетной книжки. Для выявления таких ошибок можно соединить таблицу Студенты с ее временной копией, установив в WHERE фразе равенство значений всех одноименных столбцов этих таблиц кроме столбцов с номером зачетной книжки (для последних надо установить условие неравенства значений).
Временную копию таблицы можно сформировать, указав имя псевдонима за именем таблицы во фразе FROM. Так, с помощью фразы
FROM Блюда X, Блюда Y, Блюда Zбудут сформированы три копии таблицы Блюда с именами X, Y и Z.
В качестве примера соединения таблицы с ней самой сформируем запрос на вывод таких пар блюд таблицы Блюда, в которых совпадает основа, а название первого блюда пары меньше (по алфавиту), чем номер второго блюда пары. Для этого можно создать запрос с одной копией таблицы Блюда (Копия):
SELECT Блюдо, Копия.Блюдо, Основа FROM Блюда, Блюда Копия WHERE Основа = Копия.Основа AND Блюдо < Копия.Блюдо;
или двумя ее копиями (Первая и Вторая):
SELECT Первая.Блюдо, Вторая.Блюдо, Основа FROM Блюда Первая, Блюда Вторая WHERE Первая.Основа = Вторая.Основа AND Первая.Блюдо < Вторая.Блюдо;
Получим результат вида
| Первая.Блюдо | Вторая.Блюдо | Основа |
|---|---|---|
| Морковь с рисом | Помидоры с луком | Овощи |
| Морковь с рисом | Салат летний | Овощи |
| Морковь с рисом | Салат витаминный | Овощи |
| Помидоры с луком | Салат витаминный | Овощи |
| Помидоры с луком | Салат летний | Овощи |
| Салат витаминный | Салат летний | Овощи |
| Бастурма | Бефстроганов | Мясо |
| Бастурма | Мясо с гарниром | Мясо |
| Бефстроганов | Мясо с гарниром | Мясо |
3.2.6 | Содержание | 3.3.1
Вложенный подзапрос - это подзапрос, заключенный в круглые скобки и вложенный в WHERE (HAVING) фразу предложения SELECT или других предложений, использующих WHERE фразу. Вложенный подзапрос может содержать в своей WHERE (HAVING) фразе другой вложенный подзапрос и т.д. Нетрудно догадаться, что вложенный подзапрос создан для того, чтобы при отборе строк таблицы, сформированной основным запросом, можно было использовать данные из других таблиц (например, при отборе блюд для меню использовать данные о наличии продуктов в кладовой пансионата).
Существуют простые и коррелированные вложенные подзапросы. Они включаются в WHERE (HAVING) фразу с помощью условий IN, EXISTS или одного из условий сравнения ( = | <> | < | <= | > | >= ). Простые вложенные подзапросы обрабатываютя системой "снизу вверх". Первым обрабатывается вложенный подзапрос самого нижнего уровня. Множество значений, полученное в результате его выполнения, используется при реализации подзапроса более высокого уровня и т.д.
Запросы с коррелированными вложенными подзапросами обрабатываются системой в обратном порядке. Сначала выбирается первая строка рабочей таблицы, сформированной основным запросом, и из нее выбираются значения тех столбцов, которые используются во вложенном подзапросе (вложенных подзапросах). Если эти значения удовлетворяют условиям вложенного подзапроса, то выбранная строка включается в результат. Затем выбирается вторая строка и т.д., пока в результат не будут включены все строки, удовлетворяющие вложенному подзапросу (последовательности вложенных подзапросов).
Следует отметить, что SQL обладает большой избыточностью в том смысле, что он часто предоставляет несколько различных способов формулировки одного и того же запроса. Поэтому во многих примерах данной главы будут использованы уже знакомые нам по предыдущей главе концептуальные формулировки запросов. И несмотря на то, что часть из них успешнее реализуется с помощью соединений, здесь все же будут приведены их варианты с использованием вложенных подзапросов. Это связано с необходимостью детального знакомства с созданием и принципом выполнения вложенных подзапросов, так как существует немало задач (особенно на удаление и изменение данных), которые не могут быть реализованы другим способом. Кроме того, разные формулировки одного и того же запроса требуют для своего выполнения различных ресурсов памяти и могут значительно отличаться по времени реализации в разных СУБД.
3.2.7 | Содержание | 3.3.2
Простые вложенные подзапросы используются для представления множества значений, исследование которых должно осуществляться в каком-либо предикате IN, что иллюстрируется в следующем примере: выдать название и статус поставщиков продукта с номером 11, т.е. помидоров.
| Результат: | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
SELECT Название, Статус FROM Поставщики WHERE ПС IN ( SELECT ПС FROM Поставки WHERE ПР = 11 ); |
|
Как уже отмечалось в п.3.3.1, при обработке полного запроса система выполняет прежде всего вложенный подзапрос. Этот подзапрос выдает множество номеров поставщиков, которые поставляют продукт с кодом ПР = 11, а именно множество (1, 5, 6, 8). Поэтому первоначальный запрос эквивалентен такому простому запросу:
SELECT Название, Статус FROM Поставщики WHERE ПС IN (1, 5, 6, 8);
Подзапрос с несколькими уровнями вложенности можно проиллюстрировать на том же примере. Пусть требуется узнать не поставщиков продукта 11, как это делалось в предыдущих запросах, а поставщиков помидоров, являющихся продуктом с номером 11. Для этого можно дать запрос
SELECT Название, Статус FROM Поставщики WHERE ПС IN ( SELECT ПС FROM Поставки WHERE ПР IN ( SELECT ПР FROM Продукты WHERE Продукт = 'Помидоры' ));
В данном случае результатом самого внутреннего подзапроса является только одно значение (11). Как уже было показано выше, подзапрос следующего уровня в свою очередь дает в результате множество (1, 5, 6, 8). Последний, самый внешний SELECT, вычисляет приведенный выше окончательный результат. Вообще допускается любая глубина вложенности подзапросов.
Тот же результат можно получить с помощью соединения
SELECT Название, Статус FROM Поставщики, Поставки, Продукты WHERE Поставщики.ПС = Поставки.ПС AND Поставки.ПР = Продукты.ПР AND Продукт = 'Помидоры';
При выполнении этого компактного запроса система должна одновременно обрабатывать данные из трех таблиц, тогда как в предыдущем примере эти таблицы обрабатываются поочередно. Естественно, что для их реализации тебуются различные ресурсы памяти и времени, однако этого невозможно ощутить при работе с ограниченным объемом данных в иллюстративной базе ПАНСИОН.
3.3.1 | Содержание | 3.3.3
Выдать номера поставщиков, которые поставляют хотя бы один продукт, поставляемый поставщиком 6.
| Результат: | |||||||
|---|---|---|---|---|---|---|---|
SELECT DISTINCT ПС FROM Поставки WHERE ПР IN ( SELECT ПР FROM Поставки WHERE ПС = 6); |
|
Отметим, что ссылка на Поставки во вложенном подзапросе означает не то же самое, что ссылка на Поставки во внешнем запросе. В действительности, два имени Поставки обозначают различные значения. Чтобы этот факт стал явным, полезно использовать псевдонимы, например, X и Y:
SELECT DISTINCT X.ПС FROM Поставки X WHERE X.ПР IN ( SELECT Y.ПР FROM Поставки Y WHERE Y.ПС = 6 );
Здесь X и Y √ произвольные псевдонимы таблицы Поставки, определяемые во фразе FROM и используемые как явные уточнители во фразах SELECT и WHERE. Напомним, что псевдонимы определены лишь в пределах одного запроса.
3.3.2 | Содержание | 3.3.4
Выдать номера поставщиков, находящихся в том же городе, что и поставщик с номером 6.
| Результат: | |||||
|---|---|---|---|---|---|
SELECT ПС FROM Поставщики WHERE Город = ( SELECT Город FROM Поставщики WHERE ПС = 6 ); |
|
В подобных запросах можно использовать и другие операторы сравнения (<>, <=, <, >= или >), однако, если вложенный подзапрос возвращает более одного значения и не используется оператор IN, будет возникать ошибка.
3.3.3 | Содержание | 3.3.5
Выдать название и статус поставщиков продукта с номером 11.
SELECT Название, Статус FROM Поставщики WHERE 11 IN ( SELECT ПР FROM Поставки WHERE ПС = Поставщики.ПС );
Такой подзапрос отличается от рассмотренного в п.3.3.2 тем, что вложенный подзапрос не может быть обработан прежде, чем будет обрабатываться внешний подзапрос. Это связано с тем, что вложенный подзапрос зависит от значения Поставщики.ПС а оно изменяется по мере того, как система проверяет различные строки таблицы Поставщики. Следовательно, с концептуальной точки зрения обработка осуществляется следующим образом:
( SELECT ПР FROM Поставки WHERE ПС = 1 );получая в результате множество (9, 11, 12, 15). Теперь система может завершить обработку для поставщика с номером 1. Выборка значений Название и Статус для ПС=1 (СЫТНЫЙ и рынок) будет проведена тогда и только тогда, когда ПР=11 будет принадлежать этому множеству, что, очевидно, справедливо.
Подобные подзапросы называются коррелированными, так как их результат зависит от значений, определенных во внешнем подзапросе. Обработка коррелированного подзапроса, следовательно, должна повторяться для каждого значения извлекаемого из внешнего подзапроса, а не выполняться раз и навсегда.
Рассмотрим пример использования одной и той же таблицы во внешнем подзапросе и коррелированном вложенном подзапросе.Выдать номера всех продуктов, поставляемых только одним по-ставщиком.
| Результат: | |||
|---|---|---|---|
SELECT DISTINCT X.ПР FROM Поставки X WHERE X.ПР NOT IN ( SELECT Y.ПР FROM Поставки Y WHERE Y.ПС <> X.ПС ); |
|
Действие этого запроса можно пояснить следующим образом: "Поочередно для каждой строки таблицы Поставки, скажем X, выделить значение номера продукта (ПР), если и только если это значение не входит в некоторую строку, скажем, Y, той же таблицы, а значение столбца номер поставщика (ПС) в строке Y не равно его значению в строке X".
Отметим, что в этой формулировке должен быть использован по крайней мере один псевдоним - либо X, либо Y.
3.3.4 | Содержание | 3.3.6
Квантор EXISTS (существует) - понятие, заимствованное из формальной логики. В языке SQL предикат с квантором существования представляется выражением EXISTS (SELECT * FROM ...).
Такое выражение считается истинным только тогда, когда результат вычисления "SELECT * FROM ..." является непустым множеством, т.е. когда существует какая-либо запись в таблице, указанной во фразе FROM подзапроса, которая удовлетворяет условию WHERE подзапроса. (Практически этот подзапрос всегда будет коррелированным множеством.)
Рассмотрим примеры. Выдать названия поставщиков, поставляющих продукт с номером 11.
| Результат: | ||||||
|---|---|---|---|---|---|---|
SELECT Название FROM Поставщики WHERE EXISTS ( SELECT * FROM Поставки WHERE ПС = Поставщики.ПС AND ПР = 11 ); |
|
Система последовательно выбирает строки таблицы Поставщики, выделяет из них значения столбцов Название и ПС, а затем проверяет, является ли истинным условие существования, т.е. су-ществует ли в таблице Поставки хотя бы одна строка со значением ПР=11 и значением ПС, равным значению ПС, выбранному из таблицы Поставщики. Если условие выполняется, то полученное значение столбца Название включается в результат.
Предположим, что первые значения полей Название и ПС равны, соответственно, 'СЫТНЫЙ' и 1. Так как в таблице Поставки есть строка с ПР=11 и ПС=1, то значение 'СЫТНЫЙ' должно быть включено в результат.
Хотя этот первый пример только показывает иной способ формулировки запроса для задачи, решаемой и другими путями (с помощью оператора IN или соединения), EXISTS представляет собой одну из наиболее важных возможностей SQL. Фактически любой запрос, который выражается через IN, может быть альтернативным образом сформулирован также с помощью EXISTS. Однако обратное высказывание несправедливо.
Выдать название и статус поставщиков, не поставляющих продукт с номером 11.
| Результат: | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
SELECT Название, Статус FROM Поставщики WHERE NOT EXISTS ( SELECT * FROM Поставки WHERE ПС = Поставщики.ПС AND ПР = 11 ); |
|
3.3.5 | Содержание | 3.3.7
Теперь, после знакомства с различными формулировками вложенных подзапросов и псевдонимами легче понять текст и алгоритм реализации запроса (п. 3.1) на получение тех поставщиков продуктов для Сырников, которые поставляют эти продукты за минимальную цену:
SELECT Продукт, Цена, Название, Статус FROM Продукты, Состав, Блюда, Поставки, Поставщики WHERE Продукты.ПР = Состав.ПР AND Состав.БЛ = Блюда.БЛ AND Поставки.ПР = Состав.ПР AND Поставки.ПС = Поставщики.ПС AND Блюдо = 'Сырники' AND Цена = ( SELECT MIN(Цена) FROM Поставки X WHERE X.ПР = Поставки.ПР );
Естественно, что это коррелированный подзапрос: здесь сначала определяется минимальная цена продукта, входящего в состав Сырников, и только затем выясняется его поставщик.
На этом примере мы закончим знакомство с вложенными подзапросами, предложив попробовать свои силы в составлении ряда запросов, с помощью механизма таких подзапросов:
3.3.6 | Содержание | 3.4
В литературе [2] рассматривалась реляционная операция "Объединение", позволяющая получить отношение, состоящее из всех строк, входящих в одно или оба объединяемых отношения. Но при этом исходные отношения или их объединяемые проекции должны быть совместимыми по объединению. Для SQL это означает, что две таблицы можно объединять тогда и только тогда, когда:
Например, выдать названия продуктов, в которых нет жиров, либо входящих в состав блюда с кодом БЛ = 1:
| Результат: | Продукт | |||||||
|---|---|---|---|---|---|---|---|---|
SELECT Продукт FROM Продукты WHERE Жиры = 0 UNION SELECT Продукт FROM Соста WHERE БЛ = 1 |
|
|||||||
Из этого простого примера видно, что избыточные дубликаты всегда исключаются из результата UNION. Поэтому, хотя в рассматриваемом примере Помидоры, Зелень и Яблоки выбираются обеими из двух составляющих предложения SELECT, в окончательном результате они появляются только один раз.
Предложением с UNION можно объединить любое число таблиц (проекций таблиц). Так, к предыдущему запросу можно добавить (перед точкой с запятой) конструкцию
UNION SELECT Продукт FROM Продукты WHERE Ca < 250
позволяющую добавить к списку продуктов Масло, Рис, Мука и Кофе. Однако тот же результат можно получить простым изменением фразы WHERE первой части исходного запроса
WHERE Жиры = 0 OR Ca < 250
3.3.7 | Содержание | 3.5
С помощью предложения SELECT можно реализовать любую операцию реляционной алгебры [2].
Селекция (горизонтальное подмножество) таблицы создается из тех ее строк, которые удовлетворяют заданным условиям. Пример:
SELECT * FROM Блюда WHER Основа = 'Молоко' AND Выход > 200;
Проекция (вертикальное подмножество) таблицы создается из указанных ее столбцов (в заданном порядке) с последующим исключением избыточных дубликатов строк. Пример:
SELECT DISTINCT Блюдо, Выход, Основа FROM Блюда;
Объединение двух таблиц содержит те строки, которые есть либо в первой, либо во второй, либо в обеих таблицах. Пример:
SELECT Блюдо, Основа, Выход FROM Блюда WHER Основа = 'Овощи' UNION SELECT Блюдо, Основа, Выход FROM Блюда WHER В = 'Г';
Пересечение двух таблиц содержит только те строки, которые есть и в первой, и во второй. Пример:
SELECT БЛ FROM Состав WHERE БЛ IN ( SELECT БЛ FROM Меню);
Разность двух таблиц содержит только те строки, которые есть в первой, но отсутствуют во второй. Пример:
SELECT БЛ FROM Состав WHERE БЛ NOT IN ( SELECT БЛ FROM Меню);
Декартово произведение таблиц и различные виды соединений были подробно рассмотрены в п. 3.2.1-3.2.6.
Здесь опущено лишь достаточно нудное описание редко встречаемой операция деления, которая также может быть реализована предложением SELECT с коррелированными вложенными подзапросами.
3.4 | Содержание | 3.6
Краткое знакомство с возможностями предложения SELECT показало, что с его помощью можно реализовать все реляционные операции. Кроме того, в предложении SELECT выполняются разнообразные вычисления, агрегирование данных, их упорядочение и ряд других операций, позволяющих описать в одном предложении ту работу, для выполнения которой потребовалось бы написать несколько страниц программы на алгоритмических языках Си, Паскаль или на внутренних языках ряда распространенных СУБД.
Например, пусть требуется получить калорийность и стоимость тех блюд, для которых:
Для этого можно дать запрос, показанный на рис. 3.2, позволяющий получить искомый результат в виде таблицы
| Вид | Блюдо | ||||
|---|---|---|---|---|---|
| Горячее | Помидоры с луком | калорий - | 244.6 | 0.44 | руб |
| Горячее | Бефстроганов | калорий - | 321.3 | 0.53 | руб |
| Горячее | Драчена | калорий - | 333.9 | 0.33 | руб |
| Горячее | Каша рисовая | калорий - | 339.2 | 0.27 | руб |
| Горячее | Омлет с луком | калорий - | 354.9 | 0.36 | руб |
| Десерт | Яблоки печеные | калорий - | 170.2 | 0.30 | руб |
| Десерт | Крем творожный | калорий - | 394.3 | 0.27 | руб |
| Закуска | Салат летний | калорий - | 155.5 | 0.32 | руб |
| Закуска | Салат витаминный | калорий - | 217.4 | 0.37 | руб |
| Закуска | Творог | калорий - | 330.0 | 0.22 | руб |
| Закуска | Мясо с гарниром | калорий - | 378.7 | 0.62 | руб |
| Напиток | Кофе черный | калорий - | 7.1 | 0.05 | руб |
| Напиток | Компот | калорий - | 74.4 | 0.14 | руб |
| Напиток | Кофе на молоке | калорий - | 154.8 | 0.11 | руб |
| Напиток | Молочный напиток | калорий - | 264.9 | 0.34 | руб |
| Суп | Суп молочный | калорий - | 396.6 | 0.22 | руб |
SELECT Вид, Блюдо, 'калорий -', (SUM(INT((Белки+Углев)*4.1+Жиры*9.3)*Вес/1000)), (SUM(Стоимость/К_во*Вес/1000)+MIN(Труд/100)),▓руб▓ FROM Блюда, Вид_блюд, Состав, Продукты, Наличие WHERE Блюда.БЛ = Состав.БЛ AND Состав.ПР = Продукты.ПР AND Состав.ПР = Наличие.ПР AND Блюда.В = Вид_блюд.В AND БЛ NOT IN ( SELECT БЛ FROM Состав WHERE ПР IN ( SELECT ПР FROM Наличие WHERE К_во = 0)) GROUP BY Вид, Блюдо HAVING SUM(Стоимость/К_во*Вес/1000+MIN(Труд/100)) < 1.5 AND SUM(((Белки+Углев)*4.1+Жиры*9.3)*Вес/1000) < 400 ORDER BY Вид, 4;
Рис. 3.2. Пример сложного запроса
Такой результат, нестрого говоря, строился следующим образом.
SUM(Стоимость/К_во*Вес/1000+MIN(Труд/100)) < 1.5 и SUM(((Белки+Углев)*4.1+Жиры*9.3)*Вес/1000) < 400исключаются из результата предыдущего шага.
Конечно, рассмотренный запрос весьма сложен, но попробуйте написать на любом знакомом вам языке программу, реализующую те же действия, и оцените сложность ее написания и отладки.
3.5 | Содержание | 4.1
Модификация данных может выполняться с помощью предложений DELETE (удалить), INSERT (вставить) и UPDATE (обновить). Подобно предложению SELECT они могут оперировать как базовыми таблицами, так и представлениями. Однако по ряду причин не все представления являются обновляемыми. Пока зафиксируем этот факт, отложив описание представлений и особенностей их обновления до главы 5, но будем помнить, что термин "представление" относится только к обновляемым представлениям.
Предложение DELETE имеет формат
DELETE FROM базовая таблица | представление [WHERE фраза];
и позволяет удалить содержимое всех строк указанной таблицы (при отсутствии WHERE фразы) или тех ее строк, которые выделяются WHERE фразой.
Предложение INSERT имеет один из следующих форматов:
INSERT
INTO {базовая таблица | представление} [(столбец [,столбец] ...)]
VALUES ({константа | переменная} [,{константа | переменная}] ...);
или
INSERT
INTO {базовая таблица | представление} [(столбец [,столбец] ...)]
подзапрос;
В первом формате в таблицу вставляется строка со значениями полей, указанными в перечне фразы VALUES (значения), причем i-е значение соответствует i-му столбцу в списке столбцов (столбцы, не указанные в списке, заполняются NULL-значениями). Если в списке VALUES фразы указаны все столбцы модифицируемой таблицы и порядок их перечисления соответствует порядку столбцов в описании таблицы, то список столбцов в фразе INTO можно опустить. Однако не советуем этого делать, так как при изменении описания таблицы (перестановка столбцов или изменение их числа) придется переписывать и INSERT предложение.
Во втором формате сначала выполняется подзапрос, т.е. по предложению SELECT в памяти формируется рабочая таблица, а потом строки рабочей таблицы загружаются в модифицируемую таблицу. При этом i-й столбец рабочей таблицы (i-й элемент списка SELECT) соответствует i-му столбцу в списке столбцов модифицируемой таблицы. Здесь также при выполнении указанных выше условий может быть опущен список столбцов фразы INTO.
Предложение UPDATE также имеет два формата. Первый из них:
UPDATE (базовая таблица | представление} SET столбец = значение [, столбец = значение] ... [WHERE фраза]
где значение - это
столбец | выражение | константа | переменная
и может включать столбцы лишь из обновляемой таблицы, т.е. значение одного из столбцов модифицируемой таблицы может заменяться на значение ее другого столбца или выражения, содержащего значения нескольких ее столбцов, включая изменяемый.
При отсутствии WHERE фразы обновляются значения указанных столбцов во всех строках модифицируемой таблицы. WHERE фраза позволяет сократить число обновляемых строк, указывая условия их отбора.
Второй формат описывает предложение, позволяющее производить обновление значений модифицируемой таблицы по значениям столбцов из других таблиц. К сожалению в ряде СУБД эти форматы отличаются друг от друга и от стандарта. Для примера приведем один из таких форматов:
UPDATE {базовая таблица | представление}
SET столбец = значение [, столбец = значение] ...
FROM {базовая таблица | представление} [псевдоним],
{базовая таблица | представление} [псевдоним]
[,{базовая таблица | представление} [псевдоним]] ...
[WHERE фраза]
Здесь перечень таблиц фразы FROM содержит имя модифицируемой таблицы и тех таблиц, значения столбцов которых используются для обновления. При этом, естественно, таблицы должны быть связаны между собой в WHERE фразе (см.п.3.2.3), которая, кроме того, служит для указания условий отбора обновляемых строк модифицируемой таблицы.
В значениях, находящихся в правых частях равенств фразы SET, следует уточнять имена используемых столбцов, предваряя их именем таблицы (псевдонима).
3.6 | Содержание | 4.2
Удалить поставщика с ПС = 7.
DELETE FROM Поставщики WHERE ПС = 7;
Если таблица Поставки содержит в момент выполнения этого предложения какие-либо поставки для поставщика с ПС = 7, то такое удаление нарушит непротиворечивость базы данных. К сожалению нет операции удаления, одновременно воздействующей на несколько таблиц. Однако в некоторых СУБД реализованы механизмы поддержания целостности (см.п.2.5 в литературе [2]), позволяющие отменить некорректное удаление или каскадировать удаление на несколько таблиц.
Удалить все поставки.
DELETE FROM Поставки;
Поставки - все еще известная таблица, но в ней теперь нет строк. Для уничтожения таблицы надо выполнить операцию DROP TABLE Поставки (см.п.5.2).
Удалить все мясные блюда.
DELETE FROM Блюда WHERE Основа = 'Мясо';
Удалить все поставки для поставщика из Паневежиса.
DELETE
FROM Поставки
WHERE ПС IN
(SELECT ПС
FROM Поставщики
WHERE Город = 'Паневежис');
4.1 | Содержание | 4.3.1
Добавить в таблицу Блюда блюдо:
Шашлык (БЛ - 34, Блюдо - Шашлык, В - Г, Основа - Мясо, Выход - 150)
при неизвестной пока трудоемкости приготовления этого блюда.
INSERT INTO Блюда (БЛ, Блюдо, В, Основа, Выход) VALUES (34, 'Шашлык', 'Г', 'Мясо', 150);
Создается новая запись для блюда с номером 34, с неопределенным значением в столбце Труд.
Порядок полей в INSERT не обязательно должен совпадать с порядком полей, в котором они определялись при создании таблицы. Вполне допустима и такая версия предыдущего предложения:
INSERT
INTO Блюда (Основа, В, Блюдо, БЛ, Выход)
VALUES ('Мясо', 'Г', 'Шашлык', 34, 150);
При известной трудоемкости приготовления шашлыка (например, 5 коп) сведения о нем можно ввести с помощью укороченного предложения:
INSERT INTO Блюда VALUES (34, 'Шашлык', 'Г', 'Мясо', 150, 5);
в котором должен соблюдаться строгий порядок перечисления вводимых значений, так как, не имея перечня загружаемых столб-цов, СУБД может использовать лишь перечень, который определен при создании модифицируемой таблицы.
В предыдущих примерах проводилась модификация стержневой сущности, т.е. таблицы с первичным ключом БЛ (см.п.2.4 в литературе [2]). Почти все СУБД имеют механизмы для предотвращения ввода не уникального первичного ключа, например, ввода "Шашлыка" под номером, меньшим 34. А как быть с ассоциациями или другими таблицами, содержащими внешние ключи?
Пусть, например, потребовалось добавить в рецепт блюда Салат летний (БЛ = 1) немного (15 г) лука (ПР = 10), и мы воспользовались предложением
INSERT INTO Состав (БЛ, ПР, Вес) VALUES (1, 10, 15);
Подобно операции DELETE операция INSERT может нарушить непротиворечивость базы данных. Если не принять специальных мер, то СУБД не проверяет, имеется ли в таблице Блюда блюдо с первичным ключом БЛ = 1 и в таблице Продукты - продукт с первичным ключом ПР = 10. Отсутствие любого из этих значений породит противоречие: в базе появится ссылка на несуществующую запись. Проблемы, возникающие при использовании внешних ключей, подробно рассмотрены в литературе [2], а здесь отме-тим, что все "приличные" СУБД имеют механизмы для предотв-ращения ввода записей со значениями внешних ключей, отсутст-вующих среди значений соответствующих первичных ключей.
4.2 | Содержание | 4.3.2
Создать временную таблицу К_меню, содержащую калорийность и стоимость всех блюд, которые можно приготовить из имеющихся продуктов. (Эта таблица будет использоваться шеф-поваром для составления меню на следующий день.)
Для создания описания временной таблицы можно, например, воспользоваться предложением CREATE TABLE (см.п.5.2)
CREATE TABLE К_меню ( Вид CHAR (10), Блюдо CHAR (60), Калор_блюда INTEGER, Стоим_блюда REAL);
а для ее загрузки данными √ предложение INSERT с вложенным подзапросами:
INSERT INTO К_меню SELECT Вид, Блюдо, INT(SUM(((Белки+Углев)*4.1+Жиры*9.3) * Вес/1000)), (SUM(Стоимость/К_во*Вес/1000) + MIN(Труд/100)) FROM Блюда, Вид_блюд, Состав, Продукты, Наличие WHERE Блюда.БЛ = Состав.БЛ AND Состав.ПР = Продукты.ПР AND Состав.ПР = Наличие.ПР AND Блюда.В = Вид_блюд.В AND БЛ NOT IN ( SELECT БЛ FROM Состав WHERE ПР IN ( SELECT ПР FROM Наличие WHERE К_во = 0)) GROUP BY Вид, Блюдо ORDER BY Вид, 3;
В этом запросе предложение SELECT выполняется так же, как обычно (см. описание запроса в п.3.6), но результат не выводится на экран, а копируется в таблицу К_меню. Теперь с этой копией можно работать как с обычной базовой таблицей (Блюда, Про-дукты,...), т.е. выбирать из нее даннные на экран или принтер, обновлять в ней данные и т.п. Никакая из этих операций не будет оказывать влияния на исходные данные (например, изменение в ней названия блюда Салат летний на Салат весенний не приведет к подобному изменению в таблице Блюда, где сохранится старое название). Так как это может привести к противоречиям, то подобные временные таблицы уничтожают после их использования. Поэтому программа, обслуживающая шеф-повара, должна исполнять предложение DROP TABLE К_меню после того, как будет закончено составление меню.
4.3.1 | Содержание | 4.3.3
Рассмотренное в п.3.2.3 естественное соединение двух таблиц не включает тех строк какой-либо из них, для которых нет соответствующих строк в другой таблице. Например, если в таблицу Блюда были занесены под номером 34 сведения о Шашлыке, а рецепт его приготовления не был занесен в таблицу Рецепты, то при загрузке их естественного соединения в таблицу Временная:
CREATE TABLE Временная ( Вид CHAR (8), Блюдо CHAR (60), Рецепт CHAR (560)); INSERT INTO Временная SELECT Вид, Блюдо, Рецепт FROM Блюда, Рецепты, Вид_блюд WHERE Блюда.БЛ = Рецепты.БЛ AND Блюда.В = Вид_блюд.В;
в ней не окажется строки с Шашлыком (в таблице Рецепты не обнаружен код 34, и строка с этим кодом исключена из результата).
Следовательно, в некотором смысле можно считать, что при обычном соединении теряется информация для таких несоответствующих строк. Однако иногда (как и в приведенном примере) может потребоваться способность сохранить эту информацию. В этом случае можно воспользоваться так называемым внешним соединением:
INSERT INTO Временная SELECT Вид, Блюдо, Рецепт FROM Блюда, Рецепты, Вид_блюд WHERE Блюда.БЛ = Рецепты.БЛ AND Блюда.В = Вид_блюд.В; INSERT INTO Временная SELECT Вид, Блюдо, ⌠???■ FROM Блюда, Вид_блюд WHERE Блюда.В = Вид_блюд.В AND БЛ NOT IN ( SELECT БЛ FROM Рецепты);
В результате будет создана базовая таблица
| Вид | Блюдо | Рецепт |
|---|---|---|
| Закуска | Салат летний | Помидоры и яблоки нарезать... |
| Закуска | Салат мясной | Вареное охлажденное мясо, ... |
| . . . | ||
| Напиток | Кофе черный | Кофеварку или кастрюлю спо... |
| Напиток | Кофе на молоке | Сварить черный кофе, как ... |
| Горячее | Шашлык | ??? |
где первые 33 строки соответствуют первому INSERT и представляют собой проекцию естественного соединения таблиц Блюда и Рецепты по кодам блюд (БЛ), включающую три столбца. Последняя строка результата соответствует второму INSERT и сохраняет информацию о блюде Шашлык, рецепт котого пока не введен в таблицу Рецепты.
Заметим, что для внешнего соединения нужны два отдельных INSERT...SELECT. Однако тот же результат можно получить и одним INSERT...SELECT, используя фразу UNION, объединяющую предложения SELECT из двух INSERT:
INSERT INTO Временная SELECT Вид, Блюдо, Рецепт FROM Блюда, Рецепты, Вид_блюд WHERE Блюда.БЛ = Рецепты.БЛ AND Блюда.В = Вид_блюд.В UNION SELECT Вид, Блюдо, ⌠???■ FROM Блюда, Вид_блюд WHERE Блюда.В = Вид_блюд.В AND БЛ NOT IN ( SELECT БЛ FROM Рецепты);
4.3.2 | Содержание | 4.4
Изменить название блюда с кодом БЛ=5 на Форшмак, увеличить его выход на 30 г и установить NULL-значение в столбец Труд.
UPDATE Блюда SET Блюдо = 'Форшмак', Выход = (Выход+30), Труд = NULL WHERE БЛ = 5;
Утроить цену всех продуктов таблицы поставки (кроме цены кофе - ПР = 17).
UPDATE Поставки SET Цена = Цена * 3 WHERE ПР <> 17;
Установить равной нулю цену и К_во продуктов для поставщиков из Паневежиса и Резекне.
UPDATE Поставки
SET Цена = 0, К_во = 0
WHERE ПС IN
(SELECT ПС
FROM Поставщики
WHERE Город IN ('Паневежис', 'Резекне'));
Изменить номер продукта ПР = 13 на ПР = 20.
UPDATE Продукты UPDATE Состав SET ПР = 20 SET ПР = 20 WHERE ПР = 13; WHERE ПР = 13; UPDATE Поставки UPDATE Наличие SET ПР = 20 SET ПР = 20 WHERE ПР = 13; WHERE ПР = 13;
К сожалению в единственным запросе невозможно обновить более одной таблицы, а так как код продукта входит в четыре таблицы, то пришлось выдать четыре сходных запроса. Это может привести к противоречию базы данных (нарушению целостности по ссылкам), поскольку после выполнения первого предложения таблицы Состав, Поставки и Наличие ссылаются на уже несуществующий продукт. База становится непротиворечивой только после выполнения четвертого запроса.
4.3.3 | Содержание | 4.5
Для тех, кто достаточно хорошо понял предложение SELECT, несложно овладеть конструированием предложений DELETE, INSERT и UPDATE. Но в процессе такого конструирования следует учитывать, что:
Так, SQL отвергнет предложение
INSERT INTO Выбрано SELECT (33), Т, БЛ FROM Выбрано WHERE СМ = 17;
позволяющее ввести информацию о том, что отдыхающий, сидящий на 33-м месте, выбирает тот же набор блюд, что и отдыхающий, сидящий на 17-м месте. Ввод придется осуществить через какую-либо промежуточную таблицу, например, таблицу Выбор:
DELETE FROM Выбор; INSERT INTO Выбор (СМ, Т, БЛ) SELECT (33), Т, БЛ FROM Выбрано WHERE СМ = 17; INSERT INTO Выбрано SELECT СМ, Т, БЛ FROM Выбор;
4.4 | Содержание | 5.1
Системный каталог - это набор таблиц, в которых содержится информация, необходимая для правильного функционирования СУБД: о поддерживаемых базах данных и их базовых таблицах, представлениях, курсорах, индексах, пользователях и их правах доступа к информации, правилах модификации данных и т.д. В разных СУБД, поддерживающих SQL, существует от десятка до нескольких десятков системных таблиц, структура которых ничем не отличается от уже знакомой нам структуры пользовательских таблиц.
Так, в каждой строке системной таблицы SYSTABLES хранится описание одной из таблиц пользовательских или системной баз данных. Для каждой из них указывается имя таблицы, имя пользователя, который создал эту таблицу, число столбцов в ней и ряд других элементов информации. В таблице SYSCOLUMNS содержится строка для каждого столбца каждой таблицы, в которой указано имя столбца, имя таблицы, частью которой является данный столбец, тип данных для этого столбца и много другой информации о столбце.
С помощью предложения SELECT пользователь может получить информацию из любой системной таблицы. Например, он может дать запрос на получение имен таблиц, числа их столбцов и строк, владельца и краткого описания (если таковое вводилось в базу данных):
SELRCT Tab_name,N_col,N_row,Tab_owner,Comments FROM SYSTABLES;
и получить результат, показанный на рис. 5.1,а.
Для получения же некоторых данных о столбцах таблицы Блюда можно дать запрос
SELECT Col_name, Type, Length, Comments FROM SYSCOLUMNS WHERE Tab_name = 'Блюда';
и получить результат, показанный на рис. 5.1,б.
а)
| Tab_name | N_col | N_row | Tab_owner | Comments |
|---|---|---|---|---|
| ... | ||||
| SYS_TABLES | 11 | SYSTEM | ||
| SYS_COLUMNS | 14 | SYSTEM | ||
| ... | ||||
| Блюда | 6 | 33 | KIRILLOW | Перечень блюд, известных шеф-повару |
| Поставки | 4 | 37 | GROMOW | Данные о поставляемых продуктах |
| Вид_блюд | 2 | 5 | KIRILLOW | Перечень видов блюд |
| Трапезы | 2 | 3 | GROMOW | Перечень трапез в пансионате |
| Состав | 3 | 148 | KIRILLOW | Состав блюд |
| Продукты | 11 | 17 | KIRILLOW | Таблица продуктов |
| ... | ||||
б)
| Col_name | Type | Length | Comments |
|---|---|---|---|
| БЛ | INTEGER | 4 | Код блюда |
| Блюдо | TEXT | 16 | Название блюда |
| В | TEXT | 1 | Код вида блюда (З, С, ...) |
| Основа | TEXT | 6 | Основной продукт в блюде |
| Выход | REAL | 4 | Масса порции готового блюда |
| Труд | INTEGER | 4 | Стоимость приготовления блюда (коп) |
Рис. 5.1. Результаты запросов по системным таблицам
Пользователь, не знакомый со структурой базы данных, может с помощью подобного рода запросов получить информацию о такой структуре. Для этого ему надо владеть языком SQL и немного подумать.
В заключение следует отметить, что СУБД не позволяет обновлять каталог с помощью предложений DELETE, INSERT и UPDATE. Обновление проводится только при создании, модификации или уничтожении таблиц, индексов, правил и т.п. с помощью предложений, рассматриваемых ниже.
4.5 | Содержание | 5.2
Базовые таблицы описываются в SQL с помощью предложения CREATE TABLE (создать таблицу), синтаксис которого имеет небольшие различия в различных СУБД. Однако все они поддерживают следующую минимальную форму:
CREATE TABLE базовая_таблица (столбец тип_данных [NOT NULL] [,столбец тип_данных [NOT NULL]] ...);
где тип_данных должен принадлежать к одному из типов данных, поддерживаемых СУБД (например, одному из типов данных, перечисленных в п.1.2).
Так, описание таблицы Блюда может быть записано в виде
CREATE TABLE Блюда ( БЛ SMALLINT NOT NULL, Блюда CHAR (70) NOT NULL, В CHAR (1), Основа CHAR (10), Выход FLOAT, Труд SMALLINT );
В результате создается пустая базовая таблица Блюда, а в системный каталог помещается строка, описывающая эту таблицу. Отметим, что в профессиональных СУБД имя таблицы дополняется именем пользователя, который издал предложение CREATE TABLE. Если этот пользователь зарегистрирован в системе под именем Kirillov, то в каталоге будет зарегистрирована таблица Kirillov.Блюда и указанный пользователь может обращаться к ней по имени Kirillov.Блюда или по сокращенному имени Блюда, которое использовалось во всех предшествующих примерах и будет использоваться далее.
Конструкция NOT NULL запрещает использование неопределенного значения, т.е. специального значения, которое вводится для представления "неизвестного значения" или "неприменимого значения". Например, строка поставки таблицы Поставки может содержать неопределенное значение в столбце Цена и (или) К_во (извесно, что поставщик поставляет указанный продукт, но на данный момент неизвестна цена этого продукта и (или) объем поставки).
Существующую базовую таблицу можно в любой момент уничтожить с помощью предложения DROP TABLE (уничтожить таблицу):
DROP TABLE базовая_таблица;
по которому удаляется описание таблицы, ее данные, связанные с ней представления и индексы, построенные для столбцов таблицы (см. п. 5.3).
В SQL существует также предложение ALTER TABLE (изменить таблицу), которое позволяет добавить справа к таблице новый столбец, т.е. модифицировать описание табицы. Так как без него "можно жить", а объем книги ограничен, то мы не будем здесь описывать это предложение.
5.1 | Содержание | 5.3
Для ускорения поиска данных можно создавать индексы. Индекс - это системная таблица, построенная по значениям заданного столбца заданной таблицы. В нем размещается перечень уникальных значений указанного столбца таблицы со ссылками на те ее строки, где встречаются эти значения (структура, похожая на предметный указатель книги). Например, индекс, построенный для столбца Основа таблицы Блюда, будет содержать следующие сведения:
| Значения столбца | Строки, в которых встречается такое значение | |||||||
|---|---|---|---|---|---|---|---|---|
| Кофе | 32 | 33 | ||||||
| Крупа | 20 | 21 | ||||||
| Молоко | 7 | 8 | 12 | 18 | 22 | 24 | 28 | 31 |
| Мясо | 2 | 6 | 9 | 13 | 14 | |||
| Овощи | 1 | 3 | 17 | 23 | 15 | |||
| Рыба | 4 | 5 | 10 | 11 | ||||
| Фрукты | 25 | 26 | 27 | 29 | 30 | |||
| Яйца | 16 | 19 | ||||||
Отметим, что такой индекс уже существовал (в несколько иной форме) в базе данных, хотя это обстоятельство никак не повлияло на текст иллюстрационных предложений SELECT, DELETE, INSERT и UPDATE. SQL намеренно не включает в свои конструкции ссылки на индексы. Решение о том, использовать или не использовать какой-либо индекс при обработке некоторого конкретного запроса принимается не пользователем, а оптимизатором СУБД, который учитывает множество факторов - размер таблиц, тип используемых структур хранения данных, статистическое распределение данных в таблицах и индексах и т.д. Однако чтобы оптимизатор смог использовать индексы, их нужно построить (чтобы выиграть в лотерею нужно, по крайней мере, иметь лотерейный билет).
Естественно, что поиск какого-либо значения путем последовательного перебора неупорядоченных данных будет во много раз медленнее, чем поиск с использованием упорядоченного списка (индекса). Ясно также, что таблицу можно упорядочить лишь по данным одного столбца, тогда как поиск часто приходится осуществлять по данным нескольких столбцов. По нескольким столб-цам производится и соединение таблиц. Поэтому, несмотря на то, что индексы увеличивают объем базы данных, их следует использовать как для отдельных столбцов таблицы, так и для комбинации нескольких ее столбцов (например, для комбинации: Фамилия, Имя, Отчество).
Для построения индекса в SQL существует предложение CREATE INDEX (создать индекс), имеющее формат
CREATE [UNIQUE] INDEX имя_индекса ON базовая_таблица (столбец [[ASC] | DESC] [, столбец [[ASC] | DESC]] ...);
где UNIQUE (уникальный) указывает, что никаким двум строкам в индексируемой базовой таблице не позволяется принимать одно и то же значение для индексируемого столбца (или комбинации столбцов) в одно и то же время.
Например, индексы для столбцов БЛ и Основа таблицы Блюда создаются с помощью предложений
CREATE UNIQUE INDEX Блюда_БЛ ON Блюда (БЛ); CREATE INDEX Блюда_Основа ON Блюда (Основа);
а индекс для первичного ключа (столбцы БЛ и ПР) таблицы Состав - с помощью предложения
CREATE UNIQUE INDEX Состав_БЛ_ПР ON Состав (БЛ, ПР);
В больших (более 1000 строк) таблицах поиск индексированных значений выполняется на порядок быстрее, чем поиск неиндексированных, а в очень больших таблицах - на два-три порядка.
Так может быть, если позволяет память, следует построить индексы для всех столбцов всех таблиц базы данных?
Если база данных не должна модифицироваться, то на этот вопрос можно дать положительный ответ. Однако при удалении или добавлении строки таблицы должны быть перестроены все индексы, построенные для ее столбцов, а при изменении значения индексированного столбца - индекс этого столбца. Когда модифицируется много - несколько сотен (тысяч) строк - и после модификации каждой строки перестраиваются все ее индексы, время модификации может быть на порядок (несколько порядков) больше времени модификации строк с неиндексированными столб-цами. Поэтому перед модификацией множества строк таблицы целесообразно уничтожить индексы ее столбцов, что можно сделать с помощью предложения DROP INDEX (уничтожить индекс), имеющего следующий формат:
DROP INDEX имя_индекса;
Так как индексы могут создаваться или уничтожаться в любое время, то перед выполнением запросов целесообразно строить индексы лишь для тех столбцов, которые используются в WHERE и ORDER BY фразах запроса, а перед модификацией большого числа строк таблиц с индексированными столбцами эти индексы следует уничтожить.
5.2 | Содержание | 5.4.1
В п.1.3 уже обсуждалось это понятие, а также приводились примеры его создания и использования. Напомним, что представление - это виртуальная таблица, которая сама по себе не существует, но для пользователя выглядит таким образом, как будто она существует. Представление не поддерживаются его собственными физическими хранимыми данными. Вместо этого в каталоге таблиц хранится определение, оговаривающее, из каких столбцов и строк других таблиц оно должно быть сформировано при реализации SQL-предложения на получение данных из представления или на модификацию таких данных.
Синтаксис предложения CREATE VIEW имеет вид
CREATE VIEW имя_представления [(столбец[,столбец] ...)] AS подзапрос [WITH CHECK OPTION];
где подзапрос, следующий за AS и являющийся определением данного представления, не исполняется, а просто сохраняется в каталоге;
необязательная фраза "WITH CHECK OPTION" (с проверкой) указывает, что для операций INSERT и UPDATE над этим пред-ставлением должна осуществляться проверка, обеспечивающая удовлетворение WHERE фразы подзапроса;
список имен столбцов должен быть обязательно определен лишь в тех случаях, когда:
а) хотя бы один из столбцов подзапроса не имеет имени (создается с помощью выражения, SQL-функции или константы);
б) два или более столбцов подзапроса имеют одно и то же имя;
если же список отсутствует, то представление наследует имена столбцов из подзапроса.
Например, создадим представление Мясные_блюда
CREATE VIEW Мясные_блюда AS SELECT БЛ, Блюдо, В, Выход FROM Блюда WHERE Основа = 'Мясо';
которое может рассматриваться пользователем как новая таблица в базе данных.
Уничтожение ненужных представлений выполняется с помощью предложения DROP VIEW (уничтожить представление), имеющего следующий формат:
DROP VIEW представление;
5.3 | Содержание | 5.4.2
Создав представление Мясные_блюда пользователь может считать, что в базе данных реально существует такая таблица и дать, например, запрос на получение из нее всех данных:
SELECT * FROM Мясные_блюда;
результат которого имеет вид
| БЛ | Блюдо | В | Выход |
|---|---|---|---|
| 2 | Салат мясной | З | 200 |
| 6 | Мясо с гарниром | З | 250 |
| 9 | Суп харчо | С | 500 |
| 13 | Бастурма | Г | 300 |
| 14 | Бефстроганов | Г | 210 |
Поскольку при определении представления может быть использован любой допустимый подзапрос, то выборка данных может осуществляться как из базовых таблиц, так и из представлений:
CREATE VIEW Горячие_мясные_блюда AS SELECT Блюдо, Продукт, Вес FROM Мясные_блюда, Состав, Продукты WHERE Мясные_блюда.БЛ = Состав.БЛ AND Продукты.ПР = Состав.ПР AND В = 'Г';
Если теперь возникла необходимость получить сведения о горячих мясных блюдах, в состав которых входят помидоры, то можно сформировать запрос
SELECT Блюдо, Продукт, Вес FROM Горячие_мясные_блюда WHERE Блюдо IN ( SELECT Блюдо FROM Горячие_мясные_блюда WHERE Продукт = 'Помидоры')
и получить:
| Блюдо | Продукт | Вес |
|---|---|---|
| Бастурма | Говядина | 180 |
| Бастурма | Помидоры | 100 |
| Бастурма | Лук | 40 |
| Бастурма | Зелень | 20 |
| Бастурма | Масло | 5 |
Легко заметить, что данный запрос, осуществляющий выбор данных через два представления, выглядит для пользователя точно так же, как обычный SELECT, оперирующий обычной базовой таблицей. Однако СУБД преобразует его при выполнении в эквивалентную операцию над лежащими в основе базовыми таблицами (перед выполнением проводит слияние выданного пользователем SELECT с предложениями SELECT из описаний представлений, хранящихся в каталоге).
5.4.1 | Содержание | 5.4.3
Рассмотренные в гл.4 операции DELETE, INSERT и UPDATE могут оперировать не только базовыми таблицами, но и представлениями. Однако, если из базовых таблиц можно удалять любые строки, обновлять значения любых их столбцов и вводить в такие таблицы новые строки, то этого нельзя сказать о представлениях, не все из которых являются обновляемыми.
Безусловно обновляемыми являются представления, полученные из единственной базовой таблицы простым исключением некоторых ее строк и (или) столбцов, обычно называемые "представление-подмножество строк и столбцов". Таким является представление Мясные_блюда, полученное из базовой таблицы Блюда исключением из нее столбца Труд и строк, не содержащих значение 'Мясо' в столбце Основа. Работая с ним, можно:
Однако если бы представление Мясные_блюда имело вместо столбца Выход столбец Вых_труд, полученный путем суммирования значений столбцов Выход и Труд таблицы Блюда, то указанные выше операции INSERT и UPDATE были бы отвергнуты системой. Действительно, как распределить вводимое значение столбца Вых_труд (153 или 254) между значениями столбцов Выход и Труд базовой таблицы Блюда? Была бы отвергнута и операция удаления масла из состава бастурмы, если бы ее попытались выполнить путем удаления строки ('Бастурма', 'Масло', 5) в представлении Горячие_мясные_блюда. Встает множество вопросов: надо ли удалять из базовой таблицы Блюда строку, содержащую значение 'Бастурма' в столбце Блюдо?; надо ли удалять из базовой таблицы Продукты строку, содержащую значение 'Масло' в столбце Продукт?; надо ли удалять из базовой таблицы Состав все строки, содержащие значение 5 в столбце Вес?. Последний вопрос возник потому, что при конструировании представления Горячие_мяс-ные_блюда в него не была включена информация о связях между лежащими в его основе базовыми таблицами Блюда, Состав и Продукты, и у системы нет прямых путей для поиска той единственной строки таблицы Состав, которая должна быть удалена.
Таким образом, некоторые представления по своей природе обновляемы, в то время как другие таковыми не являются. Здесь следует обратить внимание на слова "по своей природе". Дело заключается не просто в том, что некоторая СУБД не способна поддерживать определенные обновления, в то время как другие СУБД могут это делать. Никакая СУБД не может непротиворечивым образом поддерживать без дополнительной помощи обновление такого представления как Горячие_мясные_блюда. "Без дополнительной помощи" означает здесь "без помощи какого-либо человека - пользователя".
Как было указано выше, к теоретически обновляемым представ-лениям относятся представления-подмножества строк и столбцов. Однако существуют некоторые представления, которые не являются представлениями-подмножествами строк и столбцов, но также теоретически обновляемы. Хотя известно, что такие есть и можно привести их примеры, но невозможно дать их формального определения. Неверным является такое формальное определение некоторых авторов - "нельзя обновлять соединение". Во-первых, в некоторых соединениях с успехом выполняется операция UPDATE, а, во-вторых, как было показано выше, не обновляемы и некоторые представления, не являющиеся соединениями. Кроме того, не все СУБД поддерживают обновление любых теоретически обновляемых представлений. Поэтому пользователь должен сам оценивать возможность использования операций DELETE, INSERT или UPDATE в созданном им представлении.
5.4.2 | Содержание | 5.4.4
Одна из основных задач, которую позволяют решать представления, - обеспечение независимости пользовательских программ от изменения логической структуры базы данных при ее расширении и (или) изменении размещения столбцов, возникающего, например, при расщеплении таблиц. В последнем случае можно создать представление-соединение с именем и структурой расщепленной таблицы, позволяющее сохранить программы, существовавшие до изменения структуры базы данных.
Кроме того, представления дают возможность раличным пользователям по-разному видеть одни и те же данные, возможно, даже в одно и то же время. Это особенно ценно при работе различных категорий пользователей с единой интегрированной базой данных. Пользователям предоставляют только интересующие их данные в наиболее удобной для них форме (окно в таблицу или в любое соединение любых таблиц).
Наконец, от определенных пользователей могут быть скрыты некоторые данные, невидимые через предложенное им представление. Таким образом, принуждение пользователя осуществлять доступ к базе данных через представления является простым, но эффективным механизмом для управления санкционированием доступа.
5.4.3 | Содержание | 6.1
В контексте баз данных термин безопасность означает защиту данных от несанкционированного раскрытия, изменения или уничтожения. SQL позволяет индивидуально защищать как целые таблицы, так и отдельные их поля. Для этого имеются две более или менее независимые возможности:
механизм представлений, рассмотреный в предыдущей главе и используемый для скрытия засекреченных данных от пользователей, не обладающих правом доступа;
подсистема санкционирования доступа, позволяющая предоставить указанным пользователям определенные привилегии на доступ к данным и дать им возможность избирательно и динамически передавать часть выделенных привилегий другим пользователям, отменяя впоследствии эти привилегии, если потребуется.
Обычно при установке СУБД в нее вводится какой-то идентификатор, который должен далее рассматриваться как идентификатор наиболее привилегированного пользователя - системного администратора. Каждый, кто может войти в систему с этим идентификатором (и может выдержать тесты на достоверность), будет считаться системным администратором до выхода из системы. Системный администратор может создавать базы данных и имеет все привилегии на их использование. Эти привилегии или их часть могут предоставляться другим пользователям (пользователям с другими идентификаторами). В свою очередь, пользователи, получившие привилегии от системного администратора, могут передать их (или их часть) другим пользователям, которые могут их передать следующим и т.д.
Привилегии предоставляются с помощью предложения GRANT (предоставить), общий формат которого имеет вид
GRANT привилегии ON объект TO пользователи;
В нем "привилегии" - список, состоящий из одной или нескольких привилегий, разделенных запятыми, либо фраза ALL PRIVILEGES (все привилегии); "объект" - имя и, если надо, тип объекта (база данных, таблица, представление, индекс и т.п.); "пользователи" - список, включающий один или более идентификаторов санкционирования, разделенных запятыми, либо специальное ключевое слово PUBLIC (общедоступный).
К таблицам (представлениям) относятся привилегии SELECT, DELETE, INSERT и UPDATE [(столбцы)], позволяющие соответственно считывать (выполнять любые операции, в которых используется SELECT), удалять, добавлять или изменять строки указанной таблицы (изменение можно ограничить конкретными столбцами). Например, предложение
GRANT SELECT, UPDATE (Труд) ON Блюда TO cook;
позволяет пользователю, который представился системе идентификатором cook, использовать информацию из таблицы Блюда, но изменять в ней он может только значения столбца Труд.
Если пользователь USER_1 предоставил какие-либо привилегии другому пользователю USER_2, то он может впоследствии отменить все или некоторые из этих привилегий. Отмена осуществляется с помощью предложения REVOKE (отменить), общий формат которого очень похож на формат предложения GRANT:
REVOKE привилегии ON объект FROM пользователи;
Например, можно отобрать у пользователя cook право изменения значений столбца Труд:
REVOKE UPDATE (Труд) ON Блюда FROM cook;
5.4.4 | Содержание | 6.2
В п.4.4.4 рассматривался пример, в котором требовалось изменить номер продукта ПР = 13 на ПР = 20 и для этого пришлось проводить последовательное изменение четырех таблиц:
UPDATE Продукты UPDATE Состав SET ПР = 20 SET ПР = 20 WHERE ПР = 13; WHERE ПР = 13; UPDATE Поставки UPDATE Наличие SET ПР = 20 SET ПР = 20 WHERE ПР = 13; WHERE ПР = 13;
Этот пример приведен здесь для иллюстрации того, что единственная, с точки зрения пользователя, операция может потребовать нескольких операций над базой данных. Более того, между этими операциями может даже нарушаться непротиворечивость базы данных. Например, в ней могут временно содержаться некоторые записи поставок, для которых не имеется соответствующих записей поставляемых продуктов. Положение не спасает и перестановка последовательности обновляемых таблиц. Противоречивость исчезнет только после выполнения всех обновлений, т.е. выполнения логической единицы работы - полной замены номера продукта в базе данных (независимо от количества таблиц, в которых встречается номер продукта).
Теперь можно дать определение транзакции. Транзакция или логическая единица работы, - это в общем случае последовательность ряда таких операций, которые преобразуют некоторое непротиворечивое состояние базы данных в другое непротиворечивое состояние, но не гарантируют сохранения непротиворечивости во все промежуточные моменты времени.
Никто кроме пользователя, генерирующего ту или иную последовательность SQL-предложений, не может знать о том, когда может возникнуть противоречивое состояние базы данных и после выполнения каких SQL-предложений оно исчезнет, т.е. база данных вновь станет актуальной. Поэтому в большинстве СУБД создается механизм обработки транзакций, при инициировании которого все изменения данных будут рассматриваются как предварительные до тех пор, пока пользователь (реже система) не выдаст предложения:
COMMIT (фиксировать), превращающее все предварительные обновления в окончательные ("зафиксированные");
ROLLBACK (откат), аннулирующее все предварительные обновления.
Таким образом, транзакцией можно назвать последовательность SQL-предложений, расположенных между "точками синхронизации", учреждаемых в начале выполнения программы и издании COMMIT или ROLLBACK и только в этих случаях. При этом следует иметь в виду, что возможен неявный COMMIT (существует режим AUTOCOMMIT, в котором система издает COMMIT после выполнения каждого SQL-предложения) и ROLLBACK (выполняемый при аварийном завершении программы).
Ясно теперь, что пользователь должен сам решать, включать ли механизм обработки транзакций и если включать, то где издавать COMMIT (ROLLEBACK), т.е. какие последовательности SQL-предложений являются транзакциями.
Теперь о проблемах, связанных с параллельным использованием базы данных множеством разнообразных пользователей.
Большинство СУБД позволяют любому числу транзакций одновременно осуществлять доступ к одной и той же базе данных и в них существуют те или иные механизмы управления параллельными процессами, предотвращающие нежелательные воздействия одних транзакций на другие. По сути это механизм блокирования, главная идея которого достаточно проста. Если транзакции нужны гарантии, что некоторый объект (база данных, таблица, строка или поле), в котором она заинтересована, не будет изменен каким-либо непредсказуемым образом в течение требуемого промежутка времени, она устанавливает блокировку этого объекта. Результат блокировки заключается в том, чтобы изолировать этот объект от других транзакций и, в частности, предотвратить его изменение средствами этих транзакций. Для первой транзакции, таким образом, имеется возможность выполнять предусмотренную в ней обработку, располагая определенными знаниями о том, что объект в запросе будет оставаться в стабильном состоянии до тех пор, пока данная транзакция этого пожелает.
Ограниченный объем книги заставляет нас завершить на самом интересном месте обсуждение чрезвычайно важного вопроса об управлении транзакциями и параллельном их исполнении. С этим материалом мы познакомим вас в следующей книге, посвященной прикладному программированию в среде СУБД. А о средствах SQL, используемых в прикладных программах, будет кратко рассказано далее.
6.1 | Содержание | 6.3
Вложенный подзапрос:
Операции:
Параметры
Переменные:
Предикаты:
Предложения:
Предложения:
Таблицы:
Фразы:
Функции стандартные:
Основные идеи современной информационной технологии базируются на концепции, согласно которой данные должны быть организованы в базы данных с целью адекватного отображения изменяющегося реального мира и удовлетворения информационных потребностей пользователей. Эти базы данных создаются и функционируют под управлением специальных программных комплексов, называемых системами управления базами данных (СУБД).
Увеличение объема и структурной сложности хранимых данных, расширение круга пользователей информационных систем привели к широкому распространению наиболее удобных и сравнительно простых для понимания реляционных (табличных) СУБД. Для обеспечения одновременного доступа к данным множества пользователей, нередко расположенных достаточно далеко друг от друга и от места хранения баз данных, созданы сетевые мультипользовательские версии СУБД. В них тем или иным путем решаются специфические проблемы параллельных процессов, целостности (правильности) и безопасности данных, а также санкционирования доступа.
Ясно, что совместная работа пользователей в сетях с помощью унифицированных средств общения с базами данных возможна только при наличии стандартного языка манипулирования данными, обладающего средствами для реализации перечисленных выше возможностей. Таким языком стал SQL, разработанный в 1974 году фирмой IBM для экспериментальной реляционной СУБД System R. После появления на рынке двух пионерских СУБД этой фирмы - SQL/DS (1981 год) и DB2 (1983 год) - он приобрел статус стандарта де-факто для профессиональных реляционных СУБД. В 1987 году SQL стал международным стандартом языка баз данных, а в 1992 году вышла вторая версия этого стандарта.
В книгу включены наиболее важные предложения базового варианта SQL, позволяющие познакомиться с основными средствами манипулирования данными. Недостаток места не позволил подробно рассмотреть другие его конструкции. Однако и таких знаний достаточно для получения данных из баз, находящихся под управлением большинства современных СУБД (если, конечно, вам предоставят привилегии доступа к ним).
Эта книга писалась одновременно с книгой [2], поэтому и читать их целесообразно вместе, так как знакомство с одной из них облегчит понимание другой.
В предыдущих главах, рассматривая предложения SQL, мы практически не оговаривали, откуда попадают в СУБД такие запросы. Молчаливо предполагалось, что язык используется в интерактивном режиме и запросы вводятся с клавиатуры. Однако все предложения SQL, которые можно ввести с терминала, можно использовать также в прикладной программе.
Многие современные СУБД имеют собственные языки программирования, ряд которых включает в себя SQL. Другие работают с программами, написанными на одном из распространенных алгоритмических языков (Си, Паскаль или Фортран), в которые включаются предложения SQL. Для обмена информацией с частями программы, написанными на любых из этих языков, существуют специальные конструкции SQL, позволяющие работать с переменными и (или) отдельными строками таблиц.
Переменные включающего языка:
После выполнения любого предложения SQL происходит обновление системной переменной SQLCODE (в нее заносится числовой индикатор состояния). Нулевое значение SQLCODE означает, что данное предложение выполнено успешно. Положительное значение означает, что предложение выполнено, но имела место некоторая исключительная ситуация. Например, значение +100 указывает, что не было найдено никаких данных, удовлетворяющих запросу. Наконец, отрицательное значение указывает, что имела место ошибка и предложение не выполнено. Поэтому за каждым предложением SQL в программе должна следовать проверка значения SQLCODE и должно предприниматься соответствующее действие, если это значение оказалось не таким, которое ожидалось. На практике же такую проверку осуществляют после тех предложений SQL, при выполнении которых возможна исключительная ситуация).
Основная проблема "встраивания" предложения SELECT в программу заключается в том, что SELECT, как правило, порождает таблицу с множеством строк и столбцов, а включающий язык не обладает хорошими средствами, позволяющими оперировать одновременно более чем одной записью (строкой). По этим причинам необходимо обеспечить своего рода мост между уровнем множеств языка SQL и уровнем записей включающего языка. Такой мост обеспечивают курсоры. Курсор состоит, по существу, из некоторого рода указателя, который может использоваться для просмотра множества записей. Поочередно указывая каждую запись в данном множестве, он обеспечивает возможность обращения к этим записям по одной одновременно.
Однако нередко программе требуются в каждый момент времени значения только из одной строки какой-либо таблицы, и для этого используется единичное SELECT, формат которого имеет вид
SELECT [[ALL] | DISTINCT]{ * | элемент_select [,элемент_select] ...}
INTO переменная [[INDICATOR] индикаторная_переменная]
[,переменная [[INDICATOR] индикаторная_переменная]] ...
FROM базовая_таблица | представление [псевдоним]
[,базовая_таблица | представление [псевдоним]] ...
[WHERE фраза]
[GROUP BY фраза [HAVING фраза]];
где элемент_select - это одна из следующих конструкций:
[таблица.]* | [таблица.]столбец | SQL_функция | переменная | (выражение) | системная_переменная
Очевидно, что это описание отличается от описания подзапроса (п.2.1) наличием фразы INTO и включением в список элементов_select переменных. Переменные могут также включаться в выражения и фразы WHERE и HAVING.
Приведем несколько примеров. Получить общий вес продуктов в кладовой пансионата и занести его в переменную Общий_вес:
SELECT SUM(К_во) INTO Общий_вес FROM Наличие;
Здесь определяется единственное значение (сумма данных в столб-це) и поэтому системная переменная SQLCODE устанавливается в нуль.
Однако в следующем примере
SELECT Продукт, К_во INTO Продукт, К_продукта FROM Наличие, Продукты WHERE Наличие.ПР = Продукты.ПР AND ПР IN ( SELECT ПР FROM Продукты WHERE Продукт = 'Икра черная');
где требовалось узнать количество черной икры в кладовой пансионата и занести название этого продукта и его количество в переменные Продукт и К_продукта, соответственно, переменная SQLCODE примет значение +100, так как в кладовой нет икры.
Наконец, в примере
SELECT Продукт, К_во INTO Продукт, К_продукта FROM Наличие, Продукты WHERE Наличие.ПР = Продукты.ПР;
где не указан конкретный продукт и, следовательно, SELECT спродуцирует вывод всей таблицы продуктов, значение SQLCODE будет отрицательным. При этом значения переменных Продукт и К_продукта останутся неизменными, т.е. такими, какими они были после последнего правильного выполнения команды.
В единичном SELECT можно ввести за каждой целевой переменной слово INDICATOR и имя индикаторной переменной. Значения индикаторных переменных не равны нулю только при нулевом значении SQLCODE и NULL-значениях элементов SELECT для соответствующих целевых переменных. Например, если в столбцах К_во и Стоимость продукта 9 хранится значение NULL, то после выполнения запроса
SELECT ПР, К_во, Стоимость INTO ПР INDICATOR Инд1, К_прод INDICATOR Инд2, Стоим INDICATOR Инд3 FROM Наличие WHERE ПР = 9;
будут получены следующие значения переменных: SQLCODE = 0, ПР = 9, Инд1 = 0, Инд2 = Инд3 = -1, а К_прод и Стоим имеют значение NULL.
Переменные можно использовать и в предложениях модификации данных. Приведем несколько примеров.
Изменить цены продуктов ленинградских поставщиков на величину, заданную переменной Измен:
UPDATE Поставки SET Цена = Цена + .Измен WHERE ПС IN (SELECT ПC FROM Поставщики WHERE Город = 'Ленинград');
Удалить все блюда, основа которых указана в переменной Осн:
DELETE FROM Блюда WHERE Основа = .Осн;
Добавить в таблицу Поставщики нового поставщика, атрибуты которого заданы соответствующими переменными ПС, Имя, Статус, Город, а Адрес и Телефон неизвестны:
INSERT INTO Поставщики (ПС, Название, Статус, Город) VALUES (.ПС, .Имя, .Статус, .Город);
В тех же приложениях, где надо отыскивать и обрабатывать множество подходящих записей из одной таблицы или совокупности таблиц базы данных следует использовать курсоры, позволяющие организовать последовательный доступ к строкам какой-либо таблицы (соединению таблиц, представлению и т.п.).
Предложение
DECLARE имя_курсора CURSOR FOR подзапрос
определяет имя курсора и связанный с ним подзапрос. С его помощью идентифицируется некоторое множество столбцов и строк указаной таблицы (совокупности таблиц), которое становится активным множеством для данного курсора. (Точнее говоря, определяется множество частей строк, в которые входят только значения из указанных столбцов.) Курсор идентифицирует также позицию в этом множестве (сначала это позиция его первой записи). Активные множества всегда рассматриваются как упорядоченные. При этом упорядочение определяется фразой ORDER BY, а при ее отсутствии √ системой (в порядке загрузки строк в таблицу).
Описанные с помощью DECLARE CURSOR множества используются рядом предложений SQL для удаления отмеченных строк (DELETE), их модификации (UPDATE) или присвоения значений перечисленных в SELECT столбцов переменным, список которых указывается в предложении FETCH (вызвать). Однако перед выполнением этих команд необходимо активизировать курсор, который в этот момент не должен быть открыт. Для этого используется предложение OPEN (OPEN имя_курсора).
Предложение FETCH используется для выборки той записи активного множества, на которую указывает курсор, для присвоения значений столбцов этой записи переменным, перечисленным во фразе INTO, и для перемещения курсора на следующую строку активного множества. При перемещении за последнюю строку переменная SQLCODE примет значение +100.
FETCH имя_курсора
INTO переменная [[INDICATOR] индикаторная_переменная]
{,переменная [[INDICATOR] индикаторная_переменная]} ...
Команду FETCH обычно помещают в некоторый цикл, размещая непосредственно за ней команду анализа SQLCODE. Это позволяет обнаружить переход от значения 0 на +100 и организовать выход из цикла.
Наконец, следует упомянуть еще два предложения, связанные с курсорами. Это предложение для дезактивации курсора (CLOSE имя_курсора) и предложение для уничтожения курсора (DROP CURSOR имя_курсора).
Мы уже отмечали, что ограниченный объем книги не позволяет подробнее обсудить и должным образом проиллюстрировать использование курсоров. Не затронуты также предложения COMMENT ON (ввести описание таблицы или столбца), CONNECT (открыть базу данных), DISCONNECT (закрыть базу данных), WHENEVER (организовать обработку индикатора ошибки SQL) и несколько предложений, связанных с управлением транзакциями и параллельным их исполнением.
6.2 | Содержание | Литература
Реляционная база данных представляется пользователю как совокупность таблиц и ничего кроме таблиц. На рис.1.1 приведен пример реляционной базы данных ПАНСИОН. Этот простой пример используется для иллюстрации большинства вопросов, рассматриваемых в нашей книге. Поэтому советуем потратить немного времени, чтобы хорошо с ним разобраться*.
Кладовая пансионата периодически пополняется продуктами из списка, часть которого показана в таблице Продукты. Каждый продукт имеет кроме названия (столбец Продукт) уникальный номер этого продукта (столбец ПР). Химический состав продуктов приведен для 1 кг их съедобной части: основные пищевые вещества (белки, жиры и углеводы) даны в граммах, а минеральные вещества (калий, кальций, натрий) и витамины (B2, PP, C) - в миллиграммах.
В таблице Блюда представлены уникальные номера блюд (столбец БЛ), их названия, коды видов (см. таблицу Вид_блюд), основной продукт (столбец Основа), масса порции в граммах (столбец Выход) и приведенная стоимость в копейках приготовления одной порции (столбец Труд).
В таблице Рецепты приведена технология приготовления блюд. Их выделение в отдельную таблицу произведено потому, что одно и то же блюдо может иметь несколько разных рецептов.
Таблица Состав связывает между собой таблицы Блюда и Продукты, оговаривая, какая масса (в граммах) того или иного продукта (столбец Вес) должна входить в состав одной порции блюда. Так, порция блюда с номером 12 (Суп молочный) должна состоять из 350 г продукта с номером 7 (Молоко), 35 г продукта с номером 13 (Рис), 5 г продукта с номером 3 (Масло) и 5 г продукта с номером 16 (Сахар).
Шеф-повар ежедневно получает от завхоза сведения о количестве в килограммах имеющихся продуктов и их текущей стоимости (столбцы К_во и Стоимость таблицы Наличие). Используя эти сведения он определяет по таблице Состав перечень тех блюд, которые можно приготовить из этих продуктов, а также калорийность и стоимость таких блюд. При этом стоимость блюда складывается из стоимости и массы продуктов, необходимых для приготовления одной его порции, а также из трудозатрат на ее приготовление (см. таблицу Блюда). Калорийность же определяется по массе и калорийности каждого из продуктов блюда. (Для получения значения калорийности продукта исходят из того, что при окислении 1 г углеводов или белков в организме освобождается в среднем 4.1 ккал, а при окислении 1 г жиров - 9.3 ккал.)
| Блюда | Рецепты | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
| Поставщики | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| Состав | Поставки | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
| Продукты | Наличие | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
| Вид_блюд | Трапезы | Меню | Выбор | Выбрано | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 1.1. Основные таблицы базы данных ПАНСИОН
Учитывая примерную стоимость и необходимую калорийность дневного рациона отдыхающих, шеф-повар составляет меню на следующий день. В этом меню (таблица Меню) предлагается по несколько альтернативных блюд каждого вида (таблица Вид_блюд) и для каждой трапезы (таблица Трапезы). Перед завтраком каждый отдыхающий вводит в ЭВМ номер закрепленного за ним места в столовой пансионата (столбец СМ в таблице Выбор) и желаемый набор блюд для каждой из трапез следующего дня (в примере таблица заполнялась отдыхающим, сидящим на месте с номером 2). Таблицы Выбор объединяются по мере их создания в общую таблицу Выбрано, по которой определяют, сколько порций того или иного блюда надо приготовить для каждой трапезы.
Завхоз связан с поставщиками продуктов, сведения о которых хранятся в таблице Поставщики. Эта таблица содержит уникальный номер поставщика (столбец ПС), его название, статус, месторасположение и телефон.
Таблица Поставки связывает между собой таблицы Продукты и Поставщики, оговаривая, какое количество продукта (столбец К_во) и по какой цене поставил тот или иной поставщик. Отсутствие в строке цены и количества говорит о том, что поставщик ПС может поставлять продукт ПР, но в данный момент не осуществил такой поставки.
Легко заметить, что все таблицы примера (как и все таблицы любой реляционной базы данных) состоят из строки заголовков столбцов и одной или более строк значений данных под этими заголовками. Эти столбцы и строки должны иметь следующие свойства:
Почему же база данных, составленная из таких таблиц, называется реляционной? А потому, что отношение - relation - просто математический термин для обозначения неупорядоченной совокупности однотипных записей или таблиц определенного специфического вида, описанного выше. Таким образом, можно, например, сказать, что база данных ПАНСИОН состоит из одиннадцати отношений.
Реляционные системы берут свое начало в математической теории множеств. Они были предложены в конце 1968 года доктором Э.Ф.Коддом из фирмы IBM, который первым осознал, что можно использовать математику для придания надежной основы и строгости области управления базами данных.
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин "запись", который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин "кортеж длины n" или просто "кортеж", которому дал точное определение. В литературе [2,3] можно подробно познакомиться с терминологией реляционных баз данных, а здесь мы будем использовать неформальные их эквиваленты:
| таблица | для отношения, |
| строка или запись | для кортежа, |
| столбец или поле | для атрибута. |
Мы также принимаем, по определению, что "запись" означает "экземпляр записи", а "поле" означает "имя и тип поля".
* Так как иллюстративная база данных создавалась для лекционного курса в 1988 году, когда существовали "смешные" цены, а также исчезнувшие названия статусов (коопторг) и городов (Ленинград), то автор пытался несколько раз ее модифицировать. Однако поняв, что изменение цен, статусов и названий идет быстрее, чем подготовка и, тем более, выпуск издания, он решил сохранить в книге старые цены и названия.
Предисловие | Содержание | 1.2